방금 SEAN 돌리고 왔다.
코드를 뜯어 합치려니까 논문 일단 읽어야겠다
다른건 관심 없고 구조 차이를 보려고 한다.
1. SPADE
https://arxiv.org/pdf/1903.07291.pdf
[아키텍쳐 전체 구조]
인퍼런스에서 만드는건 맵만 가지고 만들겠지만 학습때는 이미지 봐야하니까.

[이미지 인코더]
간단하게 생겼다

Generator, Discriminator 구조를 각각 보자.

Generator는 SPADE ResBlock과 upsample 연산으로 구성되어있다.
Upsample은 nearest neighbor upsampling.
핵심은 SPADE ResBlock의 구조일 것이다.


Spade ResBlock의 구조이다.
{SPADE - ReLU - 3*3 Conv-k} * 2로 이루어져 있고, 두 갈래로 나눠서 연산.
k는 커널 개수이다.
그럼 저 SPADE는 뭔가.

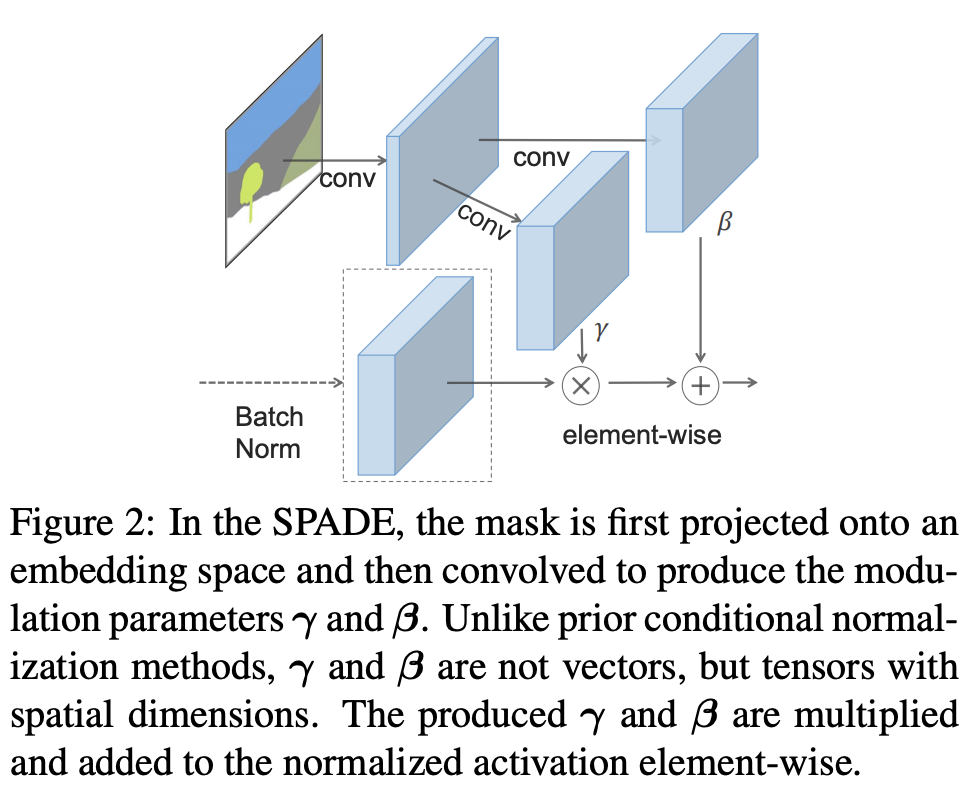
1. sync batch norm을 한다.
2. 마스크에서는 conv 연산으로 피쳐를 뽑는다.
3. 2로 뽑은 값을 가지고 input noise를 affine transform 해준다.
Discriminator는 pix2pixHD 논문을 따른다. 특징을 꼽자면 멀티스케일과 더불어 InstanceNorm(IN)을 사용.

2. OASIS
https://arxiv.org/pdf/2012.04781.pdf
인코더 사라진다. SPADE 연산이 들어가나 봐야겠다.

모델 구조는 역시 appendix 맨 뒤에 있다.
segmentation이 들어가는 D 구조.

G는 SPADE 구조인데, OASIS가 3D noise를 썼기 때문에 label map + noise를 붙이는 과정이 있다.
residual block 개수도 하나 줄였다고 한다.

아까 SPADE와 비교해보자.
그니까 ResBlock에서 원래 map만 넣어 spatially-adaptive normalization을 했는데, 거기에 3d noise도 concat한걸 계속 쓰는듯

OASIS의 3d noise의 Distribution은 어땠더라?
Appendix A.7로 가자.
세가지 방법이 있다.
- 값 하나만 뽑아 width*height만큼 tile
- 각 label (region)마다 뽑아서 tile. 그니까 랜덤벡터 뽑는거
- 그냥 전부 랜덤
ablation 결과를 보면, 이미지 전체에서 값 통일하는게 낫다. 왜냐면 그래야 복잡도가 낮아서 필요한 semantic을 더 잘 배울 수 있다나.
3. SEAN https://arxiv.org/pdf/1911.12861.pdf
고민되는게, 그럼 OASIS처럼 인코더를 없애버리면 어디서 뽑아야할까.
아까 실험한것처럼 region별로 뭔가 다르게 주고 싶은데..

공식 코드의 models/networks/normalization.py를 뜯어봤다.
일단 use_rgb option은 디폴트로 True인데, 이경우에 region-adaptive normalization을 사용하는것이며 아니면 그냥 SPADE를 사용한다.
forward() 볼건데, 참고로 이거 배치처리 아니라서 각각 이미지별로 해주는거다.
아무튼 한 이미지 내에서 클래스 개수만큼 순회하면서, 만약에 마스크 내에 해당 클래스가 존재하는 경우, FC-ReLU를 거쳐서 mu값을 뽑아준다. (=middle_mu)
참고로 여기서 fc_mu[클래스_번호]의 경우 create_gamma_beta_fc_layers()에 정의되어있고, 클래스 개수만큼 하드코딩 되어있다 ㄱ- 하나하나 정의해줘야함. 다시말해, 클래스별로 다른 FC를 가지고 있다고 생각하면 되겠다. FC input은 해당 이미지의 그 클래스의 스타일코드.
이거 reshape, expand하고, masked_scatter 거치면 middle_avg[batch]가 계산된다.
middle_avg[batch]가 계산 완료되면, gamma_avg, beta_avg 계산한다. conv 연산 각각 거쳐서 뽑는데, 둘다 인풋은 middle_avg[batch]이다.
gamma_spade, beta_spade도 있는데 이건 SPADE normalizatiton이다. (인풋으로 segmap 받아서 처리)
최종적으로, 가중치를 사용하여 region based와 spade의 것을 잘 블렌딩하여 gamma_final, beta_final를 구한다.
가중치는 하이퍼파라미터가 아니고 learnable하며, 이 값에 sigmoid 씌운 값을 블렌딩 계수로 쓴다.
final 감마 베타로 affine transform을 하는데, 이미지에다가 노이즈를 추가한 것에 affine 연산을 적용한다.
스타일 코드는 어떻게 만드는가?
architecture.py 코드를 보면 spade resblk forward() input 3번째가 style이다.
generator에서만 사용할테니 generator.py를 보면, 모델 generator forward()에서 확인할 수 있다.
self.Zencoder(input=rgb_img, segmap=seg) 의 output이 스타일 코드이며, 이걸 한번 계산한뒤 모든 resblk에서 계속 우려먹는다.
제트인코더 구조를 보자.
코드를 대충 보면, self.model()을 거친게 코드인데, 여기에 segmap을 마스크처럼 활용해가지고 select하는거다. (추가적인 변형 X)
그러면 그 model()은 어떻게 생겼는가?
ReflectionPad2d()가 뭔진 모르겠는데, 아무튼 이게 모델의 처음과 끝에 있으며, 중간은 downsample - upsample (conv와 transposed-conv) 구조로 되어있는 작은 네트워크이다.
class Zencoder(torch.nn.Module):
def __init__(self, input_nc, output_nc, ngf=32, n_downsampling=2, norm_layer=nn.InstanceNorm2d):
super(Zencoder, self).__init__()
self.output_nc = output_nc
model = [nn.ReflectionPad2d(1), nn.Conv2d(input_nc, ngf, kernel_size=3, padding=0),
norm_layer(ngf), nn.LeakyReLU(0.2, False)]
### downsample
for i in range(n_downsampling):
mult = 2**i
model += [nn.Conv2d(ngf * mult, ngf * mult * 2, kernel_size=3, stride=2, padding=1),
norm_layer(ngf * mult * 2), nn.LeakyReLU(0.2, False)]
### upsample
for i in range(1):
mult = 2**(n_downsampling - i)
model += [nn.ConvTranspose2d(ngf * mult, ngf * mult * 2, kernel_size=3, stride=2, padding=1, output_padding=1),
norm_layer(int(ngf * mult / 2)), nn.LeakyReLU(0.2, False)]
model += [nn.ReflectionPad2d(1), nn.Conv2d(256, output_nc, kernel_size=3, padding=0), nn.Tanh()]
self.model = nn.Sequential(*model)
def forward(self, input, segmap):
codes = self.model(input)
segmap = F.interpolate(segmap, size=codes.size()[2:], mode='nearest')
# print(segmap.shape)
# print(codes.shape)
b_size = codes.shape[0]
# h_size = codes.shape[2]
# w_size = codes.shape[3]
f_size = codes.shape[1]
s_size = segmap.shape[1]
codes_vector = torch.zeros((b_size, s_size, f_size), dtype=codes.dtype, device=codes.device)
for i in range(b_size):
for j in range(s_size):
component_mask_area = torch.sum(segmap.bool()[i, j])
if component_mask_area > 0:
codes_component_feature = codes[i].masked_select(segmap.bool()[i, j]).reshape(f_size, component_mask_area).mean(1)
codes_vector[i][j] = codes_component_feature
# codes_avg[i].masked_scatter_(segmap.bool()[i, j], codes_component_mu)
return codes_vector
그럼 궁금한게 있다.
OASIS의 경우 제트인코더를 사용하지 않으며, 노이즈도 3d로 계속 넣어준다는 장점이 있었다.
SEAN의 normalization 기법처럼 class별로 다르게 연산할 수 있도록하는 방법은 없을까?
OASIS 코드를 얼핏 봤는데, 3d noise injection은 generator.py에서 이뤄지며, models/norms.py의 SPADE는 그냥 우리가 아는 스페이드 normalization이 구현되어있다.
generator의 모든 resblk에서 사용할텐데, 이건 concat(random noise Z + segmentation map)을 한번 구해놓고 계속 우려먹는 식ㅇ이다.
각 resblk를 연산할때 아래와 같은 식인데, 저 x는 현재 feature map이고 (시작은 ㅇ이미지)
낼 이어서 봄 퇴근해야지
def forward(self, x, seg):
if self.learned_shortcut:
x_s = self.conv_s(self.norm_s(x, seg))
else:
x_s = x
dx = self.conv_0(self.activ(self.norm_0(x, seg)))
dx = self.conv_1(self.activ(self.norm_1(dx, seg)))
out = x_s + dx
return out'AIML 분야 > Generative Model과 GAN' 카테고리의 다른 글
| [논문리뷰] Video Inpainting - Flow-Guided Diffusion for Video Inpainting (FGDVI) (0) | 2023.12.13 |
|---|---|
| SEAN 돌려보고 이것저것 수정해보기 (2) | 2021.09.16 |
| GAN 이것저것 대충 읽기 (0) | 2021.09.14 |
| [휘리릭 논문 읽기] CVPR 2021 Best Paper: GIRAFFE (3) | 2021.08.17 |
| StyleGAN v2보다 좋은 transformer 기반 GAN이 나왔음 (0) | 2021.08.05 |



댓글