"GIRAFFE: Representing Scenes as Compositional Generative Neural Feature Fields"
Michael Niemeyer, Andreas Geiger
발표 뭐할지 고민하는 중에 이름이 귀여운 논문을 발견했다!
근데 이번 CVPR best임.
세상에... 올해 CVPR best paper조차 모르고 연구하고 있었다니 어떻게 그럴 수가 있지?
당장 읽어보도록 하자
뭐 하는 논문인가요?
이런식으로 controllable image generation을 한다.
?
뭔가 저런식으로 controllable한걸 하려는 수요는 엄청 많았을테니 연구가 많긴 했을텐데, 3D 고려해서 한게 없다는 것 같다.
왜냐면 원래 자연이 3D라는걸 고려하지 않고 이미지상에서 요소를 decompose하려는건 posteriori 추정인셈이니까.

아래 이미지를 보면, test시에 바로 이미지의 object, background의 shape & appearance를 구할 수 있고, pose부분을 바꿔서 위에 Figure2와 같은 이미지를 만들 수 있는 것으로 보인다.
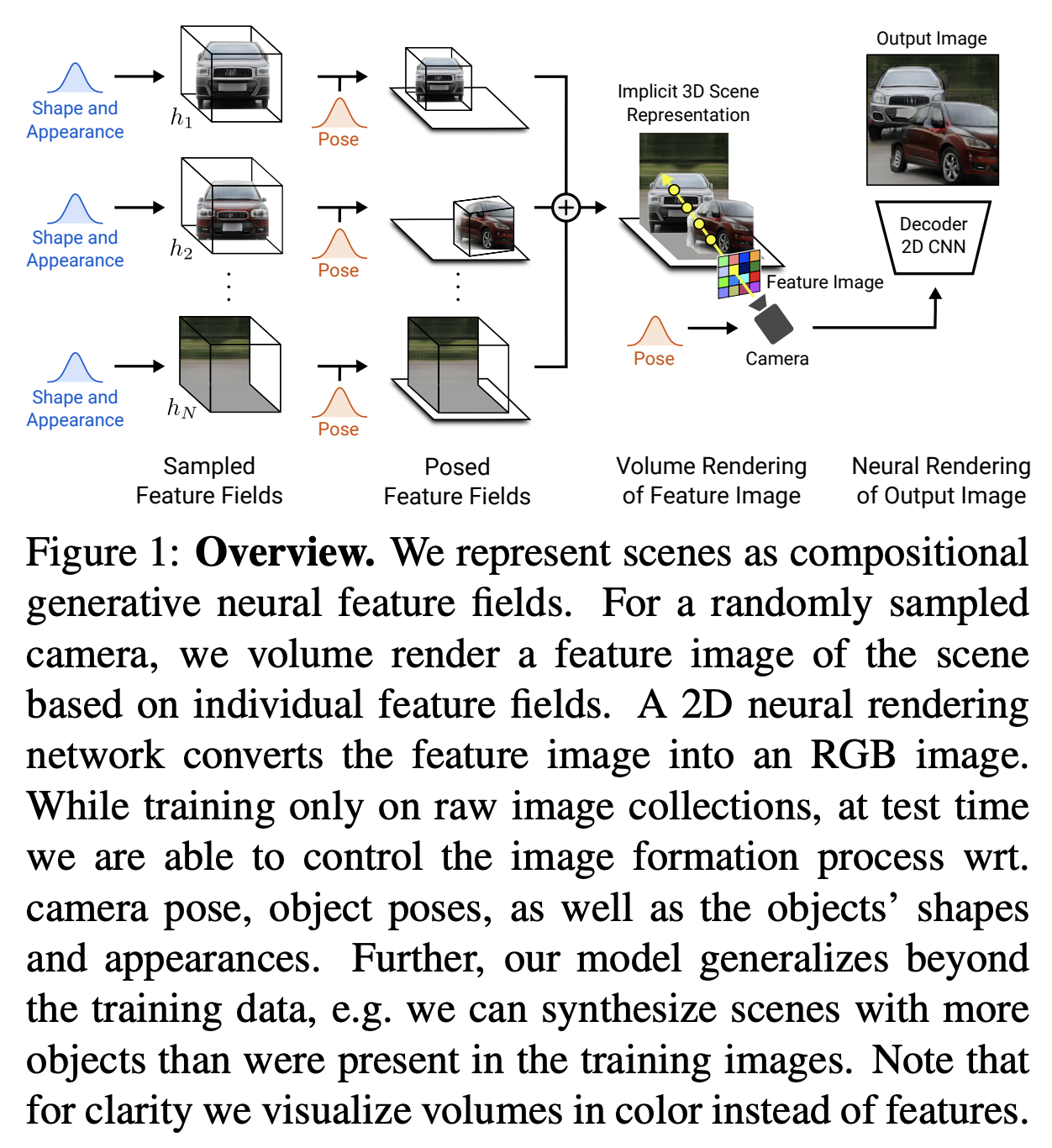
Abstract.
사실 abstract 읽어도 아키텍쳐 어케 만들었을지 전혀 감이 안 왔다. 그래도 한번 적어보면 이런 내용이다.
요즘 Generative Model들이 high resolution에서 realistic한 이미지들을 잘 만들고 있음. 1024*1024까지 커버한다.
근데 중요한건 controllable한 content generation인데, 이미지가 2D다보니까 3D정보를 이미지에서 뽑는게 어렵다. 다시말해, 데이터로부터 의미있는 representation으로 disentangle하는게 중요한 것.
우리가 살고있는 자연을 생각해보면 (nature of scene) compositional하단말임. 물체들이 각각 놓여있고 특정 각도에서 사진을 찍었을 뿐이니까. 그런데 그간 GAN 모델들은 이러한 점을 잘 고려하지 않았음.
그래서 이 논문에서는, compositionnal 3D scene representation을 generative model안에 합치겠다는 것임.
generative neural feature field라는걸 제안하고, 이걸가지고 scene을 표현하도록 했는데, 다른 supervision을 필요로 하지 않음!
또한 neural rendering pipeline이라는 것을 통해서 이미지를 잘 만든다는데.
요 핵심 키워드 두개가 어떻게 생겨먹은건지는 본문을 봐야 알 수 있다.
* []로 표기한 것은 원 논문에서 인용한 논문 그대로 적은 것.
Method.
supervision이 추가로 없음을 강조하고 시작한다.
가장 먼저, 각각의 물체를 neural feature field로 만듦.
그리고 여러 오브젝트들의 추가적인 특성들을 활용해서 scene 합성에 도움을 주도록 함.
그리고나서 렌더링에서는 volume과 neural rendering 기법을 적절히 활용함.
마지막으로 raw image collections로부터 어떻게 이 모델을 학습했는지에 대해 섹션별로 설명하겠다고 했음.
3.1. Neural Feature Field로 오브젝트를 바라보기
Neural Radiance Fields: 함수 f를 말하는건데, 얘가
3D point x와 viewing direction d를 -> volume density와 RGB color값으로 맵핑함.
당연히 f는 neural network를 사용할거니 Parameterized 되어있다.
왜 이렇게 하냐면, 저차원의 input x, d를 더 높은 dimensional feature로 맵핑을 해야 복잡한 signal들을 배울 수 있기 때문이다.
여기에 추가적으로 pre-defined positional encoding이 각 x와 d의 component(아래에 t로 표현. 스칼라값)에 적용된다.
L만큼 쪼개서 frequency domain으로 표현한 식이므로 L이 frequency octave이다.
이런 표현이 나중에 generative model에서 도움이 된다는 것을 설명할 예정이라 한다.

기존에 implicit shape representation 기법이 있었는데, 어떤 논문[61]에서 Neural Radiance Fields(NeRFs)를 MLP를 통해 학습하는 방법을 제안했었다고 한다.
아까 그 f함수인데 Lx와 Ld dimension으로 적혀있는건 input이 position encoding을 거쳤기 때문이다.

Generative Neural Feature Fields
[61]은 f의 theta 파라미터들을 튜닝하기 위해서 single scene의 multi posed images를 활용했었는데, [77]에서는 Generative Neural Feature Field(GRAF)를 제안하여 unposed image collections를 가지고 학습할 수 있게 했다. 음? 어떻게?
NeRFs의 latent space를 배우기 위해서,

이렇게 MLP에 shape과 appearance에 condition를 줬다.
shape과 appearance라는 latent code의 dimension을 Ms, Ma라고 하면, 우리가 처음에 썼던 NeRFs 식과 유사하게 아래처럼 GERF를 정의할 수 있다.

그러면 이 논문에서는 어떻게 했을까? 위의 GERF를 약간 바꿨다.
output의 density는 그대로 뒀고, 3차원의 RGB가 아니라 Mf dimension을 가지도록 일반화 했다.

근데 앞선 NeRF와 GERF의 문제는 scene단위로 표현한거. 이 논문의 목적은 scene에 있는 entity들을 disentangle하는거니까, object별로 각기 다른 feature field를 사용할 것임. 그리고나서 오브젝트들을 scene space로 옮겨주기 위해서 affine transform으로 합친다는 듯.
T = {s,t,R}
s,t는 scale, translation parameters, R은 rotation matrix.

근데 실제로 구현할때는, volume rendering은 scene space에서 하고, feature field를 evaluation 할때는 canonical object space에서 했다고 함. 각각의 Object feature fields는 파라미터 공유하고, T는 dataset-dependent distribution에서 샘플링했다고 함.

+ 아래는 저자의 사이트에 올라온 슬라이드를 캡쳐한 것.
이 파트 식이 안 와닿을 수 있어서 가져왔다.
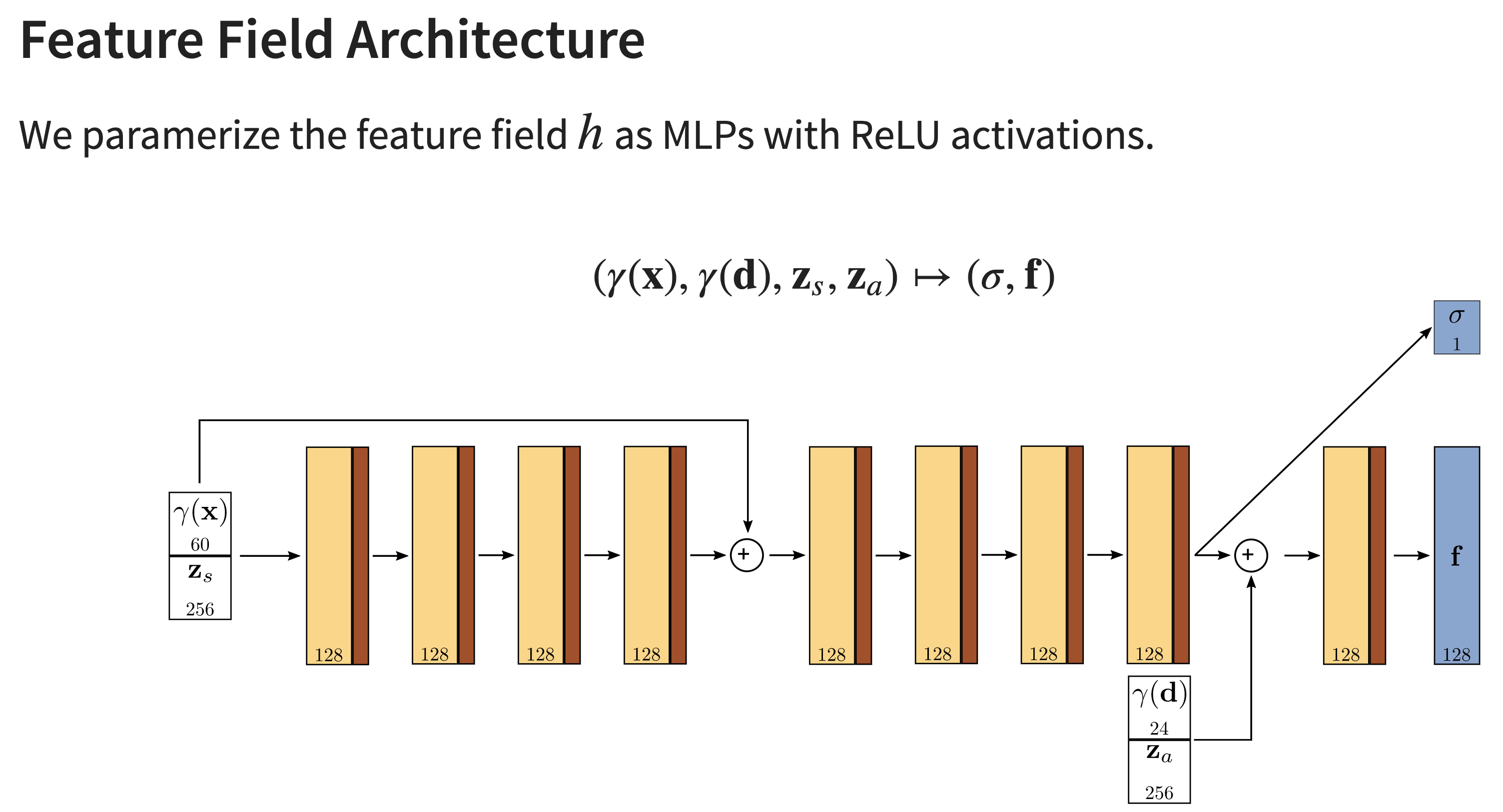
3.2. Scene Composition
이 논문에서 scene = N개의 entities의 composition으로 표현.
N-1개의 오브젝트이고 마지막 N번째는 background를 의미함.
그럼 N을 고정해? 다 다르게해?
background에는 같은 representation을 썼고, s_n, t_N의 (scale, translation params) 경우는 값을 고정해서 전체 scene을 span할 수 있게 했다.
Composition Operator (C)
모든 (x,d)의 피쳐들을 합치기 위해서 density-weighted mean을 사용했다.
시그마_i는 아까 앞에서 추정한 density, f는 피쳐 (RGB 대신이었던 그거).

이렇게하면 모든 오브젝트와 배경을 포함한 3D scene representation이 C output 하나로 aggregation 되었다고 볼 수 있을 것 같다.
3.3. Scene Rendering
이 단계에서 과정은 3D volume rendering과 2D neural rendering으로 나뉜다.
으악 복잡해; 어쩐지 이 논문 리뷰가 딱히 안보인다 했다...
3D volume rendering은 (주어진) camera extrinsic가 있을때 sample point들을 camera ray d를 따라서 sample point x와 density와 field의 feature vector들(=scene representation)을 픽셀을 위한 representation으로 바꾸는 것 같음. 이 방법도 전에 있었던 논문[37]이다.
앞에서 계산한 것들 가지고 최종적인 feature vector로 바꾼다는거.
아래 식을 보면, 역시 각 오브젝트&백그라운드의 밀도와 feature vector들을 가지고, 3D scene이 카메라에 담기는 과정을 반영해서 픽셀 도메인을 위한 feature vector로 바꿔주는 연산인거다.

참고로 N_s는 camera ray의 sample point개수라고 한다.
[61]의 numerical integration을 사용해서, f는 아래와 같이 얻을 수 있다고 함.

시그마는 밀도이고, 델타는 j와 j+1의 distance란다. sample point간의 거리. 그러니까 둘이 곱해서 volume을 구해 이를 반영해서 계산하는데, 자세한건 [61]을 봐야할 것 같다.
근데 이렇게 feature vector들을 렌더링하는데 연산이 많이 들어서 16*16으로 처리한다고함.
뒤에서 2D neural rendering을 통해 higher-resolution으로 upsample 한다고 함.
2D Neural Rendering.
neural rendering operator는 앞에서 계산한 feature image를 가지고 최종적으로 synthesized image를 RGB로 생성한다.

표현하자면 위 식이고, 연산은 CNN 기반.

정리하자면, GIRAFFE 전체 구조는 이렇다. 이름은 귀여운데 모델은 안 귀엽다.

* 3D 부분 이해하는데에 있어서, figure 1을 다시 보고오면 좋다. 내가 이해한걸 요약해보면 이렇다.
1. GERF 기반이되, scene이 아닌 object단위로 처리해서 각 오브젝트와 백그라운드의 shape, appearance를 배우게 했다.
2. pose 파라미터를 가지고 affine 변환하여 오브젝트들의 space를 scene space으로 옮겨준다.
이때 특정 오브젝트의 translation, rotation 등의 파라미터를 바꾼다면 scene domain으로 넘어갈때 이것이 반영된 representation을 생성하게 된다. (논문 visualization의 이미지를 이렇게 만들 수 있다.)
3. scene representation 하나로 합쳐야하니까, 앞에서 구한 (affine 적용한) background 및 object representation을 합쳐준다.
이제 C연산을 거쳤으니 3D scene representation을 담고있는거다!
4. 이 scene을 카메라가 담는다고 생각하자. 카메라 위치, 다시말해 extrinsic parameter에 따라 이미지가 다를거다.
3D volume rendering을 통해서, 앞에서 구한 밀도를 활용해서 pixel을 위한 feature representation으로 바꿔주자.
왜 integration하는 수식이 저렇게 나오는지에 대한 자세한 이해는 선행연구 논문[61]을 참고하는게 좋겠다.
5. 이제 카메라가 담은 pixel representation을 구한거니까, 알맞게 2D RGB이미지로 만들면 된다. Convolution이지 뭐.
이러면 우리가 지정한 pose에 맞게 이미지가 나오게 되는거다!
세세한 연산을 다 이해하진 못했지만 대략 이렇게 알아들었다.
참고로, extrinsic parameter라든가 포즈 파라미터들을 어떻게 두고 학습할지가 궁금해질거다. 거의 uniform 따르는 것 같은데, supplementary에 있다고 하니 참고하면 될 것 같다.
3.4. 학습?
Generator: 위에 그 복잡한 과정.

Discriminator: CNN + leaky ReLU.
분포 얘기는 모르겠어서 스킵.
아마 학습할때 object pose나 camera pose를 어떻게 주면서 학습할지 정하는 내용일듯 하다.

loss는 non-saturating GAN objective에다가 R1 gradient 패널티.

Experiments
single object dataset도 있고, Clevr-N을 가지고 multi object도 했다는 것 같다.
성능이 압도적으로 좋아보인다.
훌륭한 visualization은 영상으로 보는 게 좋을 것 같아서 링크를 남긴다. 아래 참고.
https://m-niemeyer.github.io/project-pages/giraffe/index.html
GIRAFFE: Representing Scenes as Compositional Generative Neural Feature Fields
Out-Of Distribution (Trained On One-Object Scenes)
m-niemeyer.github.io

controllable한 Image generation에 대한 visualization은 굉장히 많아서 이것만 가져왔다. 링크의 영상으로 보도록 하자.
이전 논문들은 안보이는 부분에 대해서 취약한데, 이 논문은 정말 굉장해!

그래도 한계점이 좀 있다고 한다.
celebA-HQ같은데서 데이터셋 바이어스가 있다고 한다.

그리고 foreground가 background element를 포함하는 경우에도 오브젝트단위의 transformation에 어려움이 있다고 한다.
'AIML 분야 > Generative Model과 GAN' 카테고리의 다른 글
| SEAN 돌려보고 이것저것 수정해보기 (2) | 2021.09.16 |
|---|---|
| GAN 이것저것 대충 읽기 (0) | 2021.09.14 |
| StyleGAN v2보다 좋은 transformer 기반 GAN이 나왔음 (0) | 2021.08.05 |
| GAN Cocktail: 학습된 GAN 모델을 합친다고? (0) | 2021.07.02 |
| [논문리뷰] Transformer + GAN에 관한 논문 리뷰 (1) | 2021.06.15 |




댓글