쓰면서 계속 추가중
코드 링크
https://github.com/ZPdesu/SEAN.git
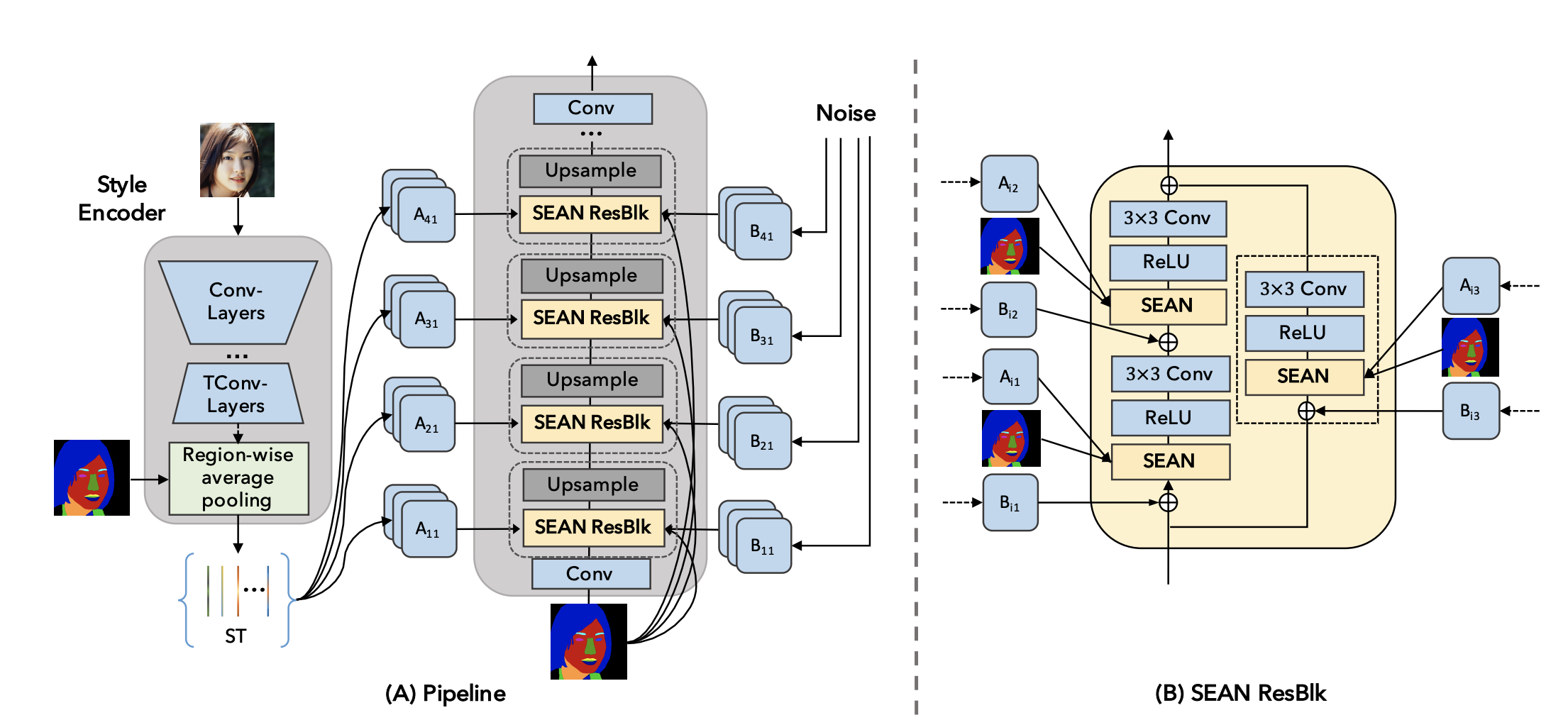
스타일을 mask로부터 인코딩할때 region별로 추출하는 구조이다.
그러면 노이즈를 주거나 하는 식으로 특정 클래스만 컨트롤 할 수 있어보여서 한번 돌려보려고 한다.
일단 하려고 하는게,
- SEAN 논문 리뷰
- 코드 돌려보고 읽어보기
- style vector 바꿔보기 -> 특정 클래스만 다양한 변화를 줘보자
- OASIS 기반으로 옮기는 대신에, normalization만 SEAN 방식으로 바꿔주기
잘 모르고 하는 소리라 뭐가 안맞거나 불가능한 부분이 있을수는 있겠는데 아무튼 도전
1. 이것저것 다운
- CelebA-HQ 데이터 다운
- 깃허브 클론 후 requirements.txt 설치. torch 1.2를 쓴다.
- pretrained tar 파일 다운
2. inference 해주기
그냥 깃허브 나온대로 하면 된다. 복잡한 부분 없었음.
results/에 결과가 저장되는데, input label map과 SEAN으로 생성한 이미지, 그리고 스타일코드가 나온다.

style code는 총 19개 클래스.
CelebA-HQ Mask dataset은 512*512 크기로 19 클래스에 대해 어노테이션이 되어있기 때문.
각 이미지에 모든 클래스가 있는건 아니기 때문에 input 레이블맵에 있는 클래스만 스타일코드가 나온다.
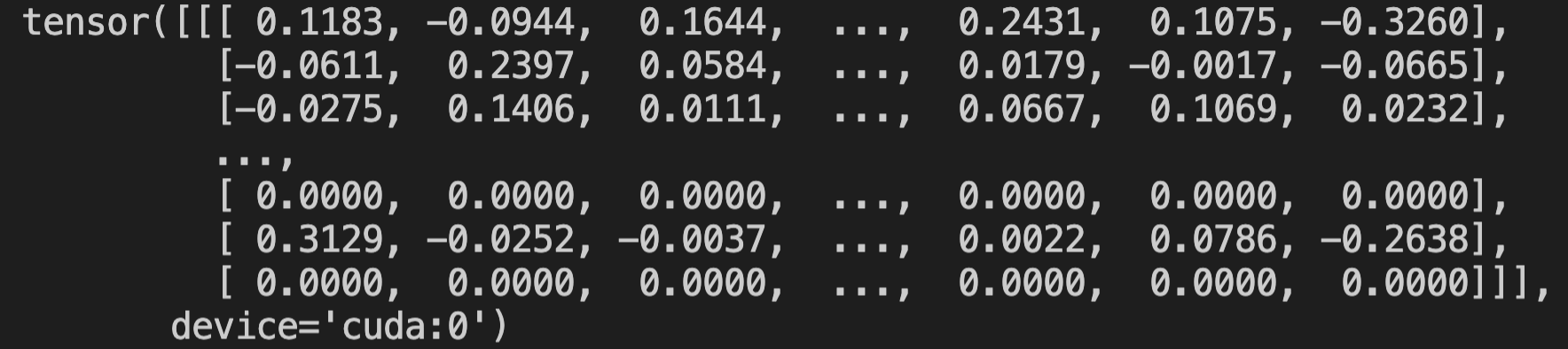
각 클래스별로 512 사이즈의 벡터가 있으며, mean을 찍어보면 0에 가까운 값이 나온다. -0.01, -0.07 이런식.
(예시) round(2) 한것.

3. 스타일 바꾸기.
models > networks > generator.py
forward()에서 models.networks.architecture에 있는 Zencoder를 가지고 style code 뽑는 부분이 있다.
[1, 19, 512]이며, 마스크에 없는 클래스에 대해서는 0으로 나온다.
확인했으면 이제 바꿔볼까.
models > networks > architecture.py의 ZEncoder forward()를 수정하였다.
두가지 실험을 진행해봤다.
- 랜덤 noise 추가하기
- 다른 이미지의 스타일을 가져오기
1.
gaussian noise를 추가해봤으나 그렇게 의미있는 변화가 있진 않았다. 예를 들면 진짜 입술같은 느낌이 아니라 색이 보라색 주황색 이렇게 좀 이상하게 변하는 수준.
분포를 N(0,sig)로 둘지 N(style vector mean, style vector std)로 할지도 고민했는데, 별 차이 없었다.
sig값이 작으면 변화가 잘 없고, 값이 크면 너무 이상해져서 마스크별로 값을 잘 조절해야했다.





2.
3번 클래스가 오른쪽 눈인 것 같은데, 이전에 인퍼런스하며 뽑았던 스타일을 기억했다가 그 다음 인퍼런스할 스타일로 교체했다.
코드는 아래에 달아놓겠다
<규칙>
왼쪽 눈은 변화 없음, 오른쪽 눈은 직전에 인퍼런스한 이미지의 오른쪽 눈 style vector로 교체
- 사진1: 이전 이미지
- 사진2: 현재 이미지
- 사진3: 현재 이미지의 원본 (synthesized X)
왼쪽 아저씨가 0번타자라서 이분은 바꾼거 없다.
가운데 있는 분의 오른쪽 눈이 아저씨 스타일로 바뀌었다.
배경의 빛이라든가 마이크 얼룩은 어떻게 안거지? 테스트셋이라 memorization도 아닌데
눈의 style vector 내에는 동공의 색, 쌍커풀 유무, 동공의 위치같은 정보를 가지고 있는 듯 하다.















각 클래스 번호별 의미가 뭔지 CelebA 홈페이지나 논문을 봐도 딱히 발견하지 못해서 그냥 하나하나 해봐서 찾음. 공식 문서 없나요
class Zencoder(torch.nn.Module):
def __init__(self, input_nc, output_nc, ngf=32, n_downsampling=2, norm_layer=nn.InstanceNorm2d):
super(Zencoder, self).__init__()
self.output_nc = output_nc
self.prev = None #
model = [nn.ReflectionPad2d(1), nn.Conv2d(input_nc, ngf, kernel_size=3, padding=0),
norm_layer(ngf), nn.LeakyReLU(0.2, False)]
### downsample
for i in range(n_downsampling):
mult = 2**i
model += [nn.Conv2d(ngf * mult, ngf * mult * 2, kernel_size=3, stride=2, padding=1),
norm_layer(ngf * mult * 2), nn.LeakyReLU(0.2, False)]
### upsample
for i in range(1):
mult = 2**(n_downsampling - i)
model += [nn.ConvTranspose2d(ngf * mult, ngf * mult * 2, kernel_size=3, stride=2, padding=1, output_padding=1),
norm_layer(int(ngf * mult / 2)), nn.LeakyReLU(0.2, False)]
model += [nn.ReflectionPad2d(1), nn.Conv2d(256, output_nc, kernel_size=3, padding=0), nn.Tanh()]
self.model = nn.Sequential(*model)
def forward(self, input, segmap):
codes = self.model(input)
segmap = F.interpolate(segmap, size=codes.size()[2:], mode='nearest')
# print(segmap.shape)
# print(codes.shape)
b_size = codes.shape[0]
# h_size = codes.shape[2]
# w_size = codes.shape[3]
f_size = codes.shape[1]
s_size = segmap.shape[1]
codes_vector = torch.zeros((b_size, s_size, f_size), dtype=codes.dtype, device=codes.device)
for i in range(b_size):
print(i)
for j in range(s_size):
component_mask_area = torch.sum(segmap.bool()[i, j])
if component_mask_area > 0:
codes_component_feature = codes[i].masked_select(segmap.bool()[i, j]).reshape(f_size, component_mask_area).mean(1)
## add noise in specific class
import numpy as np
if (j in [3]):
print(self.prev)
if (self.prev is None):
self.prev = codes_component_feature.cpu().detach().numpy()
else:
tmp = codes_component_feature.cpu().detach().numpy()
codes_component_feature = torch.Tensor(self.prev).cuda()
self.prev = tmp
#m, s = codes_component_feature.mean().cpu().detach(), codes_component_feature.std().cpu().detach()
#codes_component_feature = codes_component_feature + torch.Tensor(np.random.normal(m, s, 512)).cuda()
codes_vector[i][j] = codes_component_feature
# codes_avg[i].masked_scatter_(segmap.bool()[i, j], codes_component_mu)
return codes_vector
확실히 region based로 style vector를 뽑아 normalization을 하다보니, 인퍼런스할때 특정 구간만 건드리는게 가능했다.
4.
그럼 이걸 진짜 OASIS로 옮기는게 가능한지를 알려면 SEAN과 OASIS 코드를 뜯어봐야지
오아시스로 옮기는 이유는 이게 학습시간이 SPADE와 차이가 많이 난대서 그렇다. SEAN은 SPADE 아키텍쳐 기반이니까.
하.... 코드 뜯으러감.
'AIML 분야 > Generative Model과 GAN' 카테고리의 다른 글
| [논문리뷰] Video Inpainting - Flow-Guided Diffusion for Video Inpainting (FGDVI) (0) | 2023.12.13 |
|---|---|
| SPADE, OASIS, SEAN 모델만 빠르게 (0) | 2021.09.16 |
| GAN 이것저것 대충 읽기 (0) | 2021.09.14 |
| [휘리릭 논문 읽기] CVPR 2021 Best Paper: GIRAFFE (3) | 2021.08.17 |
| StyleGAN v2보다 좋은 transformer 기반 GAN이 나왔음 (0) | 2021.08.05 |



댓글