고전이라 이름은 많이 들어봤고, 직접 해본적은 없고, 논문은 길고, 검색하면 그래서 이 논문이 뭘한거지 싶어서 매우 대충 이것저것 읽은 기록
그냥 GAN (NIPS 14)
검색하면 경찰과 위조지폐 얘기가 잔뜩 나올테니 패스

Pix2Pix CVPR 2017

conditional GAN이 생각보다 일반적인 이미지 -> 이미지 모델에 다양하게 쓰일 수 있음을 시사하는 논문
generation시에 random noise z만 주는게 아님. 데이터 x도 준다.
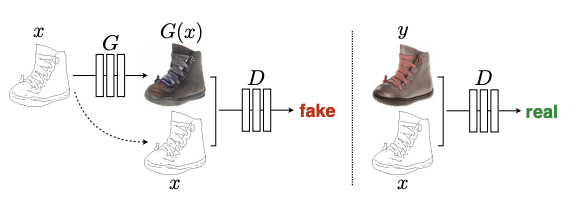

참고로 디코더는 PixelGAN 썼다. real/fake를 패치 단위로 판단한다.


ICCV 17 CycleGAN

그림으로 설명 끝남


UNIT, MUNIT은 여기 정리 잘 되어있다.
https://velog.io/@tobigs-gm1/UNIT
Unsupervised Image-to-Image Translation
Unsupervised Image-to-Image(UNIT/MUNIT/FUNIT 리뷰) [작성자 : 이도연]
velog.io
UNIT (NIPS 17)
이미지 두장이 있다고 생각하자. 얘네는 각 도메인에서의 marginal distribution을 가지고 있는데, 이걸 shared-latent space를 가진다는 가정하에 동일한 벡터로 맵핑해준다.
이미지1을 E1(.)를 통해 인코딩 한 것이 = 이미지2를 E2(.)을 통해 인코딩 한것과 같다.


CVPR 19 https://arxiv.org/abs/1903.07291 SPADE
먼저, 이 논문의 분양는 conditional image synthesis이다. Input을 뭘 주느냐에 대해서도 다양한 논문이 있는데, 이 논문에서 다루는 것은 input으로 semantic segmentation map을 주면 photo-realistic 이미지를 만들도록 하는 분야이다.
기존 논문에서는 input으로 layout을 주고 normalization, convolution 연산들, non linearity 연산들을 거치는 구조였다.
SPADE의 contribution은 spatially-adaptive normalization을 사용하는 것인데, 이유는 앞에 normalization 때문에 semantic 정보를 날려버리기 때문이다.
normalization에 대해서 생각해보자. 이 논문에서는 두가지로 분류했다. 추가적인 데이터가 필요하지 않은 unconditional normalization layer와, 그 반대인 conditional normalization layer이다.
unconditional에는 AlexNet의 local response normalization, InceptionNet의 BN, 그외에도 IN, LN, GN, WN 등이 있다.
conditional에는 conditional BN, adaptive IN 등이 있다는데, 이에 해당하는 기법의 일반적인 구조는 다음과 같다.
- 먼저, layer activation을 N(0,1)로 초기화
- learnt affine transform을 적용해서 denormalization한다. 이때, external 정보를 활용해서 affine을 구함.
- 기존에 style transfer의 경우, output의 global style을 컨트롤하는데 affine parameter를 썼던거라서 spatial coordinates로는 uniform하다고 한다. 근데 이 논문에서는 semantic map을 쓰기 때문에 그렇지 않다고 함.
Spatially adaptive denormalization은 아래처럼 생겼다. 참고로 감마, 베타는 벡터가 아니라 텐서이다. 그래서 spatially adaptive하다는건가.
암튼 normalization laye에는 항상 이걸 쓰도록 했다.

확실히 논문의 visualization을 보면 디테일이 더 사는 것 같다.
그럼 OASIS로 넘어가볼까. ICLR 21
https://openreview.net/pdf?id=yvQKLaqNE6M


1. perceptual loss 안써도 된다.
원래 GAN 모델들이 Perceptual loss에 굉장히 의존적이었던게, 얘가 없으면 엣지 정보도 이상하고 퀄리티가 나쁜 이미지가 나왔다. 물론 다양성이 떨어진다는 단점(texture, color bias)이 있는 것으로 알려져있으나 SPADE에서도 이 로스를 활용하였다.
하지만 SPADE는 adversarial loss만 사용한다. 왜 이게 가능한가?
우선, perceptual loss는 간단하게 말하면 VGG-19를 거쳐 feature space에서 계산한 유클리디안 거리이다.
일반적인 super resolution의 MSE loss의 경우 픽셀을 가지고 계산했는데 이를 보완한 것이다.
OASIS의 경우 특이한 discriminator 구조로 인해 perceptual loss를 사용하지 않아도 된다. 실제로 논문에서 ablation을 위한 실험을 제외하고는 이 로스를 사용하지 않았다고함.
2. Discriminator가 segmentation 기반이다. output이 label map이다!
SEAN
이 논문의 경우, SPADE baseline인데 두가지 다른 점이 있다
1. 이미지가 아니라 region별로 다른 style code를 사용한 점
2. noise벡터를 아키텍쳐 초반에만 넣는게 아니라 군데군데에서 넣어줌
Visualization을 보면 region별로 다르게 한 것 때문인지 스타일 변화가 잘 되는 것 같다.
암튼 spade의 space-adaptive normalization과는 다른 region-adaptive normalization을 사용한댔으니 이거 구조만 한번 보자.
우선 batch norm을 적용한 후 여기에 affine을 적용하는 구조인건 같다.
여기에 필요한 감마와 베타를 구하는데, 하나는 마스크에서 뽑고, 다른건 style matrix에서 뽑는다. 스타일별로 별개의 conv를 적용해줘서 스타일 맵을 뽑아서 적용한다.
스타일은 마스크로 부터 인코딩하여 추출

'AIML 분야 > Generative Model과 GAN' 카테고리의 다른 글
| SPADE, OASIS, SEAN 모델만 빠르게 (0) | 2021.09.16 |
|---|---|
| SEAN 돌려보고 이것저것 수정해보기 (2) | 2021.09.16 |
| [휘리릭 논문 읽기] CVPR 2021 Best Paper: GIRAFFE (3) | 2021.08.17 |
| StyleGAN v2보다 좋은 transformer 기반 GAN이 나왔음 (0) | 2021.08.05 |
| GAN Cocktail: 학습된 GAN 모델을 합친다고? (0) | 2021.07.02 |




댓글