그냥 SOTA 모델 공부해서 찾아서 돌리기 식으로 하다보니 History가 부족한 것 같아서 찾아봤다.
이번 기회에 빠삭하게 알아보겠어.
일단 써놓고 예전 포스팅이랑 합치기도 해야겠다.
Fully Convolutional Network (FCN)
원 논문은 14년 아카이브에 떴고 CVPR 15였다.
https://arxiv.org/abs/1411.4038 (논문) 새삼 기술의 발전이 빠르다... 7년 되었네요
- 일반 classification은 ConvNet + fully connected layer (FC)로 이루어져있다.
- 1*1 conv로 FC를 대체했다. 그러면 모두 conv 연산으로 이루어져 FCN이라 부른다. (이유: 위치 정보를 잃지 않기 위하여)
- 참고로 이 논문이 나온 시절을 생각해보면 당연하지만, backbone은 VGG같은거 썼다. (VGG 설명)
[잠깐 딴 소리 좀 할게요]
그나저나 VGG는 왜 FC가 3개지?
- 누군가의 질문 https://stats.stackexchange.com/questions/212344/why-do-we-have-normally-more-than-one-fully-connected-layers-in-the-late-steps-o
이에 대한 답변: 다들 여러 방법으로 튜닝해서 디자인함. GoogLeNet같은건 1레이어 썼다더라 - quora 답변 https://www.quora.com/What-is-the-purpose-of-using-more-than-1-fully-connected-layer-in-a-convolutional-neural-network 아무래도 CNN을 통해 고양이나 강아지 등 여러 feature들을 잘 뽑았으면 이 관계에 대해서도 임베딩 해야하는데, 그 관계가 복잡할 수 있어서. 그런데 이건 또 네트워크마다 다를 수 있다.
- input HW가 레이어를 거치면서 채널이 늘고 크기는 줄어든다. 예를 들어 H,W가 각각 1/32배 줄어든다.
- 1*1 conv output으로 class 개수만큼의 채널을 가지도록 한다. (마지막 feature dim. 이것을 저해상도의 class presence heatmap이라 이해하면 편하다.)
- 여기서 transposed conv를 통해 upsampling 하면서 다시 원본 HW 크기로 돌아온다. => FCN-32s 탄생
[참고] transposed conv 연산 자체에 대한 설명과 gif는 여기에.
stride-1값을 z로 지정해 모든 픽셀 간 zero padding을 하고 우리가 아는 연산을 수행함. (엄밀히 말하면 deconv는 값을 되돌릴 수 있어야하는데, transposed는 사이즈만 맞추면 되는 것. 근데 말을 혼용해서 쓰는 듯. 아무튼 여기서는 transposed 개념이 맞다.)
transposed conv 개요와 함께 상세한 설명은 여기에. 구현이 위에것인지 이 방법인지는 잘 모르겠다.
torch 구현은 이렇게. https://pytorch.org/docs/stable/generated/torch.nn.ConvTranspose2d.html
- (pool5를 그냥 쓰지 않고 2배 upsampling한 것) + (pool4) -> HW/16 사이즈
- 위의 HW/16 사이즈 feature map을 가지고 *16 upsampling하여 원본으로 만든 다음 prediction을 한다. => FCN-16s
- (아까 만든 HW/16 피쳐를 *2 upsample 한 것) + (pool3) -> HW/8 사이즈
- 위의 HW/8 사이즈 feature map을 가지고 *8 upsampling하여 원본으로 만든 다음 prediction을 한다. => FCN-8s


U-Net
헐. 지금 찾아보니 U-Net 원논문이 MICCAI 2015였다. CVPR인줄. 갑자기 MICCAI 부심이 생겨납니다.
https://arxiv.org/abs/1505.04597 (논문)
- Contracting Path, Expanding path로 나뉜 것을 아래 그림에서 볼 수 있다.

Contracting Path
- VGG 구조
- 잘 보면 3*3에 padding이 없어서 이미지가 조금씩 줄어들긴함
- 2*2 max pooling + stride=2하면, 이미지를 격자로 나눠서 중복 없이 4픽셀 중 하나 뽑기 되어서 가로세로가 절반으로 줄어든다.
- 여러 스케일에서 image context 포착
Expanding Path
- FCN 아이디어의 확장
- 같은 spatial size에서는: 채널 수를 절반으로 줄이도록 3*3 conv 연산. (역시나 padding X)
- spatial size를 늘릴 때는: 2*2 up convolution (transposed conv와 단어가 혼용된다. 같은 말)
- 참고로 padding이 없다보니 skip connection으로 이미지를 떙겨오려고 하면 사이즈가 다소 안맞는데, center crop해서 가져와 concat한다.
Result
- 따라서, 23 layer의 fully convolutional network 구조이다.
- padding을 안 써서 mask 최종 출력이 원본 이미지 크기와는 다르다. 연산과정에서 이미지 상하좌우 boundary 부분이 사라지기 때문.
- 요즘이야 그냥 이미지 넣으면 resize 알아서 해서 쫙 마스크를 만들어주는걸로 대충 생각하지만, 이 논문은 MICCAI였고 segmentation이 주료 의료영상에서 썼다는걸 생각하자. 거대한(?) 의료 이미지를 통째로 넣는건 아니고, 모델의 input size에 맞춰서 잘라 넣어 인식했다는거.
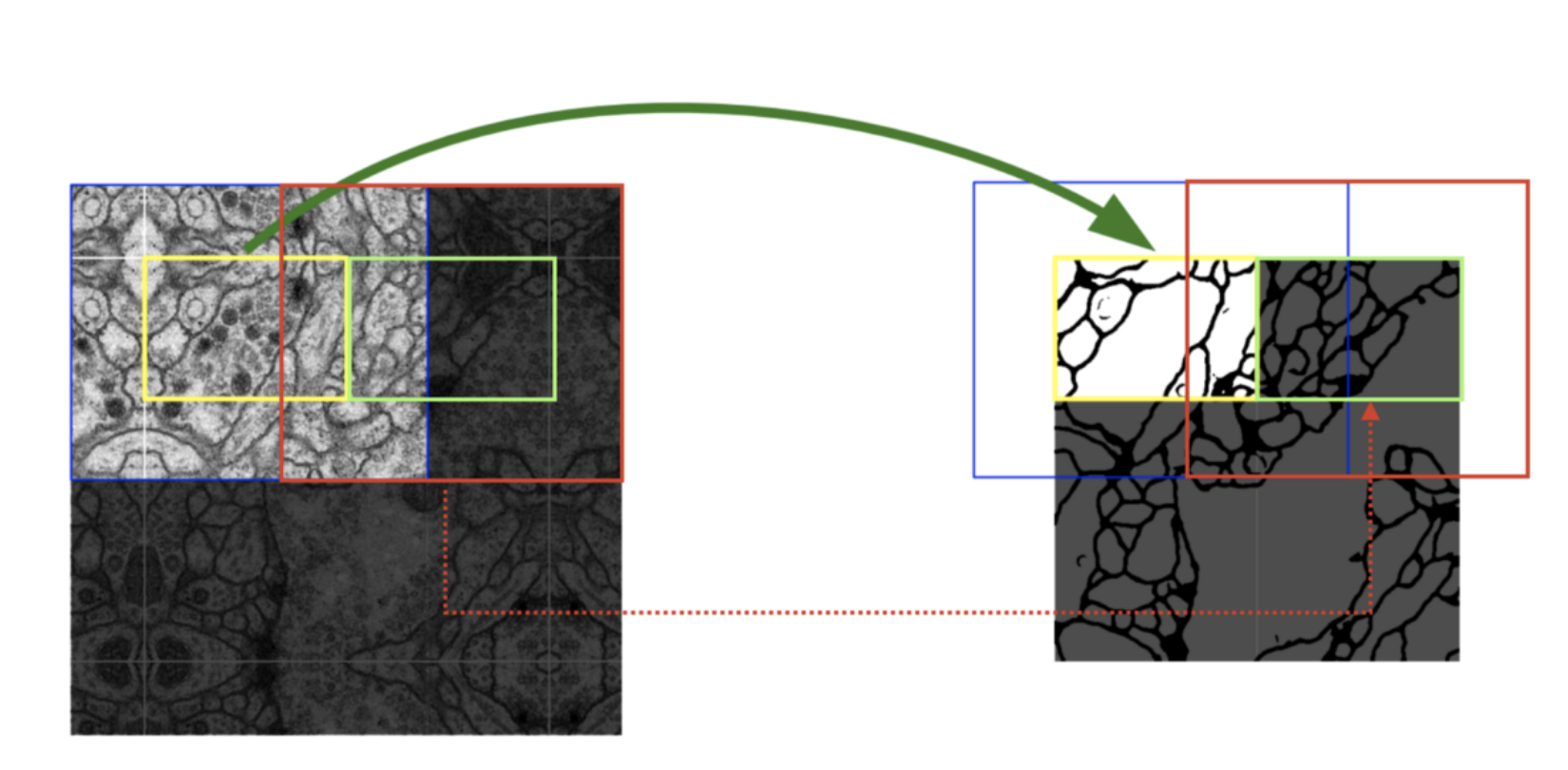
- (아래 그림 참고) 그래서 모델 input에 약간 overlap을 주면 다음 부분의 segmentation 결과가 빈곳 없이 채워지도록 할 수 있음/
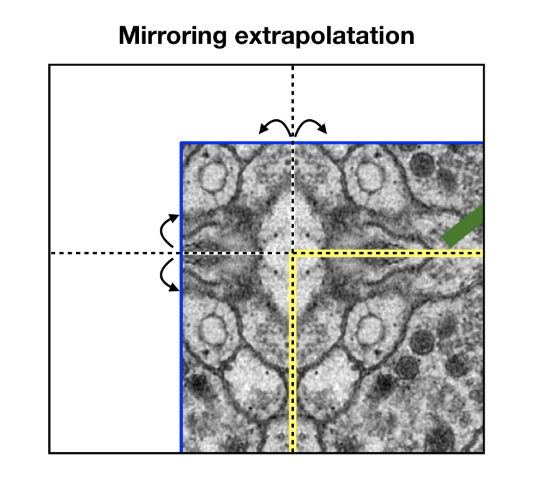
- (아래 그림 참고) 다만 전체 이미지 상하좌우 빈 부분은 결과가 없기 때문에 채워야하는데, mirroring extrapolation을 한다.
DeepLab 시리즈
먼저, 딥랩은 1, 2, 3, 3+ 버전이 있다.
- V1: atrous convolution (dilated conv) 적용
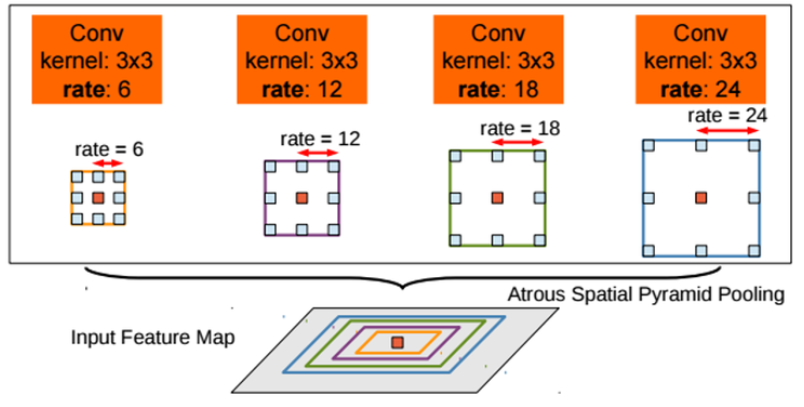
- V2: multi-scale context 적용을 위해 ASPP (Atrous Spatial Pyramid Pooling)모듈 제안
(여담: 이거 요즘 depth estimation 보는중인데 여기서도 보이드라) - V3: ResNet 구조에 dilated conv 적용.
- V3+: separable convolution과 atrous convolution을 결합한 atrous separable convolution 제안
(ResNet -> Xception으로 바뀜. inception with separable conv.)
겁나 대충봐도 알겠지만, atrous (dilated) convolution을 사용하는 게 핵심이다. ASPP module, 그리고 atrous separable conv에 대해 알아봐야겠다.
1. Atrous Convolution? (Dilated Conv)
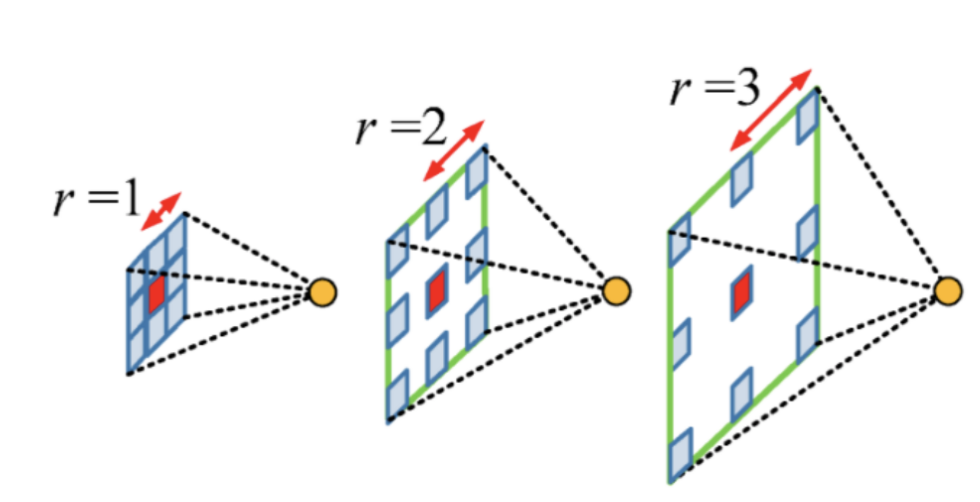
kernel내에 zero padding을 추가하여 receptive field를 넓힘! learnable 파라미터수는 늘어나지 않지만!
2. Atrous Spatial Pyramid Pooling
Spatial Pyramid Pooling?
참고할만한 것
- PSPNet을 참고하면 좋을 듯. 나눠서 연산한다음 upsample하고 concat하여 합침. ASPP 설명과 PSPNet 그림 참고
- object detection쪽을 참고하면 좋다. SPPNet obj detection 블로그 설명
뭐 이런식으로 세세한 것도 중요하고 receptive field가 넓은 것도 중요한 경우, 이렇게 pooling을 다르게 여러번 한 정보를 합쳐서 사용하는 기법이 있다. 딥랩이 사용한 Atrous Spatial Pyramid Pooling도 비슷하다고 생각하면 될 것 같다.

pooling을 쓰는건 아니고, 각기 다른 rate의 dilated conv들을 활용하여 pyramid 형태로 보고 정보를 합치겠다는 의미다.
이 그림이 가장 이해하기 쉽다. 블로그 출처 (ASPP 모듈 성능이 아주 잘 되어있으며, 코드구현을 포함하는 블로그글)
conv 결과를 만들건데, 3*3 size 커널이니까 값은 동일하게 9개임. 그런데 거리 rate가 달라서 저렇게 receptive field가 다양할 수 있다는 것.
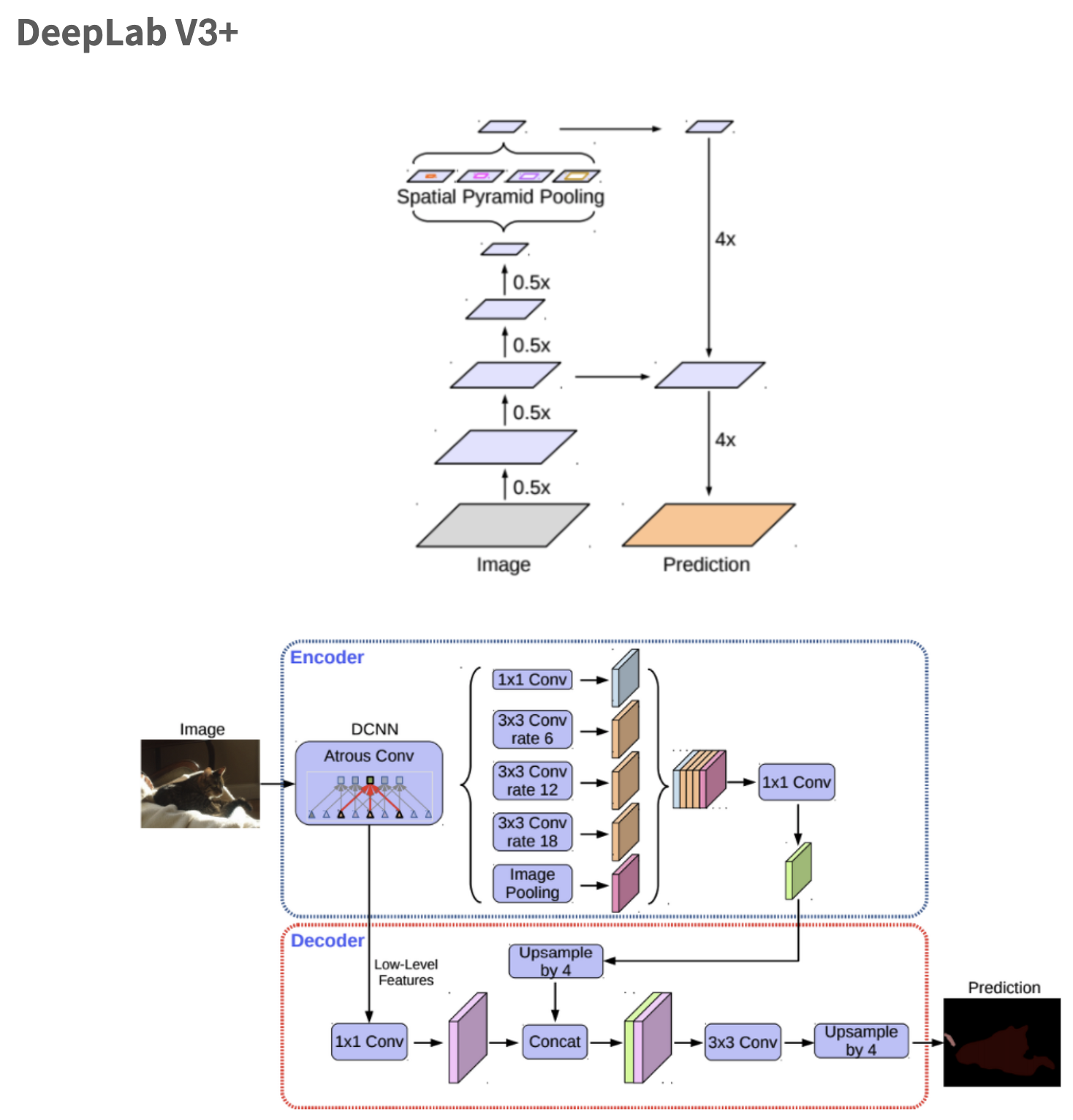
딥랩V3+로 넘어오면서 백본을 Xception 쓰는것도 그렇고, ASPP에도 separable 연산 쓰는것도 그렇고, Depthwise separable convolution을 적극적으로 활용하여 파라미터 개수 대비 성능을 좋게 하려고 했다.
딥랩 부분은 맨아래 [자료참고] 첫번째 블로그에 자세히 되어있어서 나중에 정리하려함.
이후 연구도 좀 찾아봐야할 것 같은데,
- UperNet (18년 논문이지만, 나중에 SwinTransformer가 나오면서 저 모델을 써서 SOTA를 깸)
- HRNet (여러가지 분야에 쓰이는 backbone) + OCR (뒷부분 모듈에 중점을 둔 SOTA격)
- OCR 나온 이후에는 잘모르겠다. 요즘 트랜스포머 메타인데 transformer 키워드 말고 개별 알고리즘으로 OCR보다 우수한게 있어보이진 않았다. (전에 아주 대충 확인했을때)
[자료 참고]
https://wooono.tistory.com/267 FCN, UNet, DeepLab 등 정리글. 흐름 잡는데에 많은 도움을 받음.
https://velog.io/@guide333/U-Net-%EC%A0%95%EB%A6%AC UNet 설명은 여기를 참고함
https://koreapy.tistory.com/931?category=919111 U-Net extrapolation 설명은 여기를 참고했음, 코드도 잘 정리된 글
https://nanonets.com/blog/semantic-image-segmentation-2020/ 2021 guide for semantic segmentation. Dataset, Eval metric, seg models, video와 point cloud까지 잘 다루고 있다.
TODO List (보강 예정)
- 딥랩과 ASPP 더 자세히 보기
- depthwise separable convolution (mobileNet 다시 봐야하던가?)
- Inception, Xception
- 각각의 구현




댓글