Multiscale Context, Relational Context, Coarse-to-fine Segmentation, Region-wise segmentation 이렇게 네가지로 소개하고 있다.
빨리 메서드가 읽고 싶어서 스킵했다.
위에 그림에 나왔던 ASPP가 multi-scale context를 사용한 대표적인 예시 중 하나이다.
Methods
OCR 설명에 들어가기에 앞서, 먼저 multiscale context와 region based context에 대해 정의하고 간다.
multiscale context.
딥랩v3에 있는 것과 같은 ASPP.
p라는 position이 있고, t는 position index. K는 커널. 따라서 시그마 아래에 있는 p+dt를 보면, 아래 식은 dilated convolution을 의미.
딥랩v3에서는 d값으로 12, 24, 36을 사용한 것으로 보면 된다.
이런 방법을 쓰면 resolution 손해를 안보고 연산이 가능하다. PSPNet의 방법으로도 multiscale이 가능하지만, 이건 large scale에서는 context 정보가 손실된다.
relational context.
이미지 I, w_is는 input x의 x_i, x_s 간의 relation.
로오, 델타 기호는 각기 다른 transform function을 의미한다. 이를테면 self-attention에서의 것과 같은 것이다.
본론으로 들어가면 대략적인 구조는 이렇다.
백본은 이미 거쳤다고 가정하자. 저번에 봤던 HRNet 같은거 지나서 feature map 가지고 있다고 생각.
(HRNet W48 사용)
논문 읽다보니 구현을 보는 게 더 간단할 것 같다는 생각이 든다.
1. 모든 픽셀을 soft object region으로 structurize 하기. 총 K개가 나온다고 하자. 이 object region map M={M1, ... , Mk}은 일종의 coarse segmentation map으로 생각하면 된다. 2D map 형태이다.
그렇다면 이 object region generator의 구성은 어떨까. linear 연산을 사용한다. 1*1 conv. GT segmentation을 가지고 pixel-wise CE loss로 학습.
[Object Region Representation] 2. 해당 object region에 포함되는 픽셀 끼리 모아서 -> aggregation 하기! 그러면 각 region별로 함축된 representation을 얻을 수 있을 것이다. 이 representation을 f_k라 하자. 당연히 K개가 있겠다.
[Object contextual representations] 3. 그 representation을 augment 할 것이다. object region에 대한 정보 f_k에다가, 그 region에 포함되는 모든 픽셀의 relation 정보를 적절히 고려해서.
여기 relation 정보인 w는 softmax를 통해 계산된다. 아래의 K(x_i, f_k)는 normalize되지 않은 relation 값이라고 한다.
이렇게 두 함수를 거치는 것으로 구현했는데, 둘다 1*1 Conv, BN, ReLU 순서의 연산을 가지고 있다. self attention같은 느낌으로 이 연산 위주로 OCR module을 구현한 것 같다.
또한 로우, 델타 함수는 둘다 1*1 conv, BN, ReLU 후 non local block을 적용하는 연산을 의미한다.
[Augmented representations.] 4. 그렇다. 연산 g()는 또 1*1 BN ReLU이다. 최종적으로 original representation이랑 context representation을 잘 섞어주는 것이 최종 output z_i라고 한다.
참고로, 지금까지 1*1 BN ReLU는 Input channel 256, output channel 512로 구현했다고 한다.
잠깐 궁금해져서 찾아봤다. 코드가 HRNet 구현을 기반으로 했기 때문에 기본은 똑같이 생겼고, forward에 아래 부분이 추가되었다.
세부 구현은 실험할때 보는걸로.
Experiments
앞서 언급했듯이 5개의 데이터셋에 대해 실험했다. 셋팅은 생략한다. LIP만 확인해봤는데 HRNet과 거의 비슷하다.
먼저, Context 정보를 보고 segmentation을 해주는 기존 논문과의 성능비교를 했다. 앞에 그림에 있던 ASPP처럼 말이다.
두번째로는 relation을 보기 위해 기존에 있는 방법들과 OCR을 비교했다고 한다.
이를 위해 backbone의 경우 Dilated ResNet-101로 고정했다고 한다.
모델 규모는 이렇다.
앞에서는 OCR 모듈 자체의 성능 우수성을 봤다고 하면, 아래는 정말 SOTA를 찍기위한(?) 실험이다.
백본을 dilated ResNet101 쓸 게 아니라 더 발전된 Xception, WideResNet, HRNet 등을 사용했다.
여기에 추가로 generalization 능력을 알아보기 위해서 더욱 어려운 task인 panoptic segmentation에도 적용해봤다고 한다.
COCO dataset을 사용했다. (저번에 돌려본 그거)
panoptic-FPN을 기반으로, 여기에 OCR을 추가하면 성능이 오르는지를 확인해보았다.
성능이 많이 오르는 것을 확인했다.
참고로 Appendix를 보면 panoptic에 같은 조합에다가 ASPP를 사용한 것과도 비교실험이 있는데, 역시 OCR이 더 좋았다.
이제 성능이 좋다는건 알겠는데, 그러면 드는 의문이있다. 정말로 soft object region 구한 게 의미가 있나?
물론 GT segment를 가지고 학습했으니까 의미가 있겠지만, 이를 증명하려면 visualization이 필요하다.
그래서 appendix 부분을 보면 이 내용이 있다.
Double-Attention이 relational context를 학습하는 기법인데, 이는 related work에서도 언급하지만 GT를 주지 않고 unsupervised 학습한다. 그래서인지 K=64로 큰 값을 넣었을 때 가장 잘 되었는데, 배운 region을 보면 직관성이 떨어진다.
그에 비해 supervised 학습한 OCR의 경우, K=19이지만 잘 되는 것을 알 수 있다.
실험을 스르륵 읽어서 정확하게는 모르겠는데, 아마 cityscapes가 evaluation에서는 class수가 19이기 때문에 K=19로 학습한 것 같다.
정리.
많은 실험을 통해 모델을 검증한 논문이었다.
정리하자면, 우선 input x (코드에서는 feats)을 가지고 soft region을 나눈다.
region을 GT로 supervised하게 배워주고, 이건 그냥 linear로 1*1 conv로 배우게 했었다.
그리고 softmax를 통해, 어떤 region과 해당 픽셀끼리 연관이 있는지에 대한 정보를 배워 이걸 relation 정보로 얻었다. 이게 w였다.
이걸 가중치로 가지고 곱해서 representation을 얻었고 (y. 코드에서는 context), 최종적으로는 x, y를 합쳐줘서 z representation을 얻었다.
(이렇게 얻은 것을 classification head에 넣어 최종적인 segmentation 결과를 얻는 것으로 보인다.)
이러한 연산과정에서 주로 1*1 Conv - BN - ReLU를 추가하여 사용한다. Transform function을 추가한 것이다.
Non linearity를 위해서 non local block을 덧대기도 했었다.
GT로 배웠기 때문에 region을 더 잘 배울 수 있었으며, 이로써 pixel 각각에 대한 segmentation을 정말 잘 할 수 있게 되었다.
아래 그림을 보면, 어쩌면 multiscale로 이미지에서의 맥락만 봤으면 baseline처럼 segment가 나뉘어서 나올 수 있었을 부분도 깔끔하게 떨어지는 결과를 도출한 것을 알 수 있다. (단, 이 이미지가 trainset인지 아닌지는 논문에 나와있지 않다.)
결과적으로 이런 intuition이 semantic segmentation 성능의 향상으로 귀결되었다.

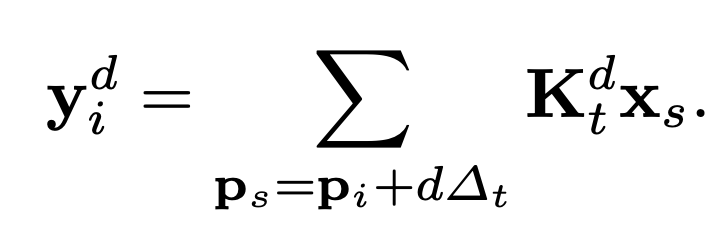



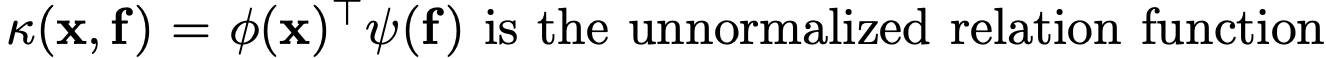

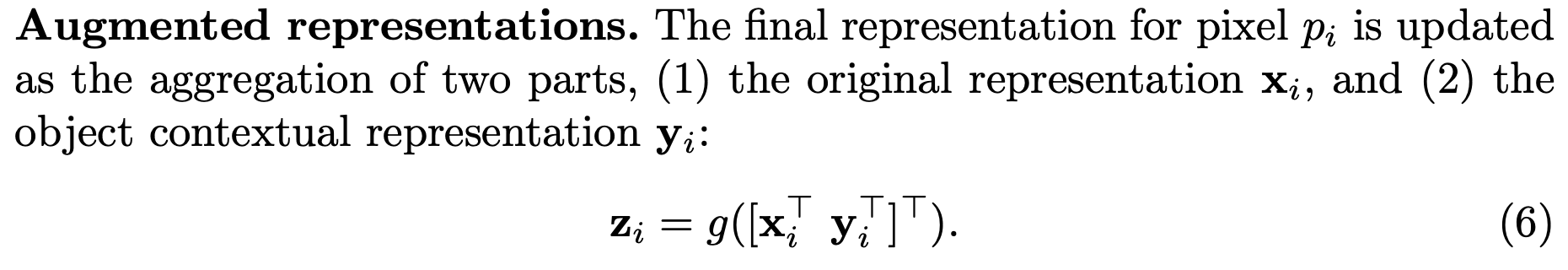













댓글