[이전 글]
방금 따끈따끈하게 작성한 이쪽 계열 연구 찍먹하는 글: https://ambitious-posong.tistory.com/175
- 주로 아키텍쳐 관점에서 봤음
- 실험 시나리오는 이제 봐야함
-> 아............. AliProducts와 AliProducts2를 헷갈렸다 ㅡㅡ
[현재 목표]
- AliProduct 챌린지 정보 찾기
챌린지 공식 사이트, 과거 우승한 tech report 및 논문 등 - ALBEF 논문 찾아보기 (foundation model, SOTA로 보임)
- image retrieval 조사
- AliProduct 데이터셋 논문읽기 마무리
꼼꼼하게 보진 않아서 혹시라도 건질게 있나 더 보기.
그런데 별로 기대는 하지 않음...
=> 역시나 retrieval 얘기 없음 - WebVision 챌린지, 데이터셋 정보 찾기
- task에 대해 정확히 이해하기 위하여, 뭐 다른 자료가 있나 찾기
TMI
이 계열에서 많이 쓰던 데이터셋은 label noise라는 관점에서 두가지로 나뉜다.
CIFAR, ImageNet같은 clean label dataset에 인위적으로 label noise를 추가하는 방식과, 원래 데이터셋 자체에 label noise가 존재하는 Clothing-1M과 WebVision 이렇게 있다.
근데 label noise 추가하기 위해 랜덤하게 바꾸거나 헷갈리도록 두 클래스 flip 시키는 등의 방법을 쓰지만, 원래 데이터셋에 내포된 것 만큼 자연스럽게 noisy하진 않을 것이다.
ALBEF 논문 정보
논문 링크: https://arxiv.org/pdf/2107.07651.pdf
visual+language model이며, 여러가지 V+L downstream task에서 테스트를 했다.
종류가 많은데 딱히 볼 필요는 없을 것 같아서 지금 필요한 image-text retrieval만 확인하려고 한다.
뭔가 ITR에서 visualization 이쁘게 된거 없나 싶었는데 task가 워낙 많아서 안보임..

AliProducts Challenge 정보
자료 찾다가 알게된건데, 2020, 2021, 2022 챌린지별로 task가 다르다고 한다.
전에는 image classification이었는데 이제는 retrieval이라 참고할 필요가 없어보인다 ㄱ-...
아니 그럼 사이트에 그 논문을 링크 걸지 말라고 ㅡㅡ
[과거 챌린지]
CVPR21 AliProduct challenge의 technical report이다.
- 이 데이터셋이 나올 당시에는 ViT가 유행하지 않아서 CNN에 대해서만 나왔는데, 이 챌린지 참가자는 ViT를 사용했기에 한번 봐야할 것 같다.
- 코드 또한 공개되어있다는 것이 장점
- 하지만 위의 이유로 이제 쓸모 없다
https://paperswithcode.com/paper/solution-for-large-scale-long-tailed
Papers with Code - Solution for Large-scale Long-tailed Recognition with Noisy Labels
Implemented in one code library.
paperswithcode.com
[CVPR22 챌린지?]
AliProducts2 dataset을 쓴다고 한다.
아니 그러면서 논문은 왜 AliProducts 데이터셋(2 아님)을 걸어두는데? 개빡치네
아무튼 참고 자료는 없고, 챌린지 사이트의 설명이 전부라고 생각하면 될 것 같다.
워크샵 페이지
https://retailvisionworkshop.github.io/recognition_challenge_2022/

챌린지 페이지
https://tianchi.aliyun.com/competition/entrance/531951/information
CVPR 2022 AliProducts Challenge: Large-scale Cross-Modal Product Retrieval-Competition introduction-Tianchi competition-Alibaba
tianchi.aliyun.com
제출 포맷은 이렇다.
caption이 주어지면 (5만개의 query에 해당하는 label이 아닌 text information인듯) 여기에 해당하는 이미지를 뱉어야한다.
top-K recall로 계산한다.

규칙을 보니 image encoder의 경우 ImageNet, WebVision pretraining 가능하다. 다른 데이터셋은 안되는듯.
text encoder에는 데이터 제한이 없다고 한다.
AliProducts Dataset 정보
그냥 챌린지 사이트 확인하자.
얘네가 인용 걸어둔 "Weakly Supervised Learning with Side Information for Noisy Labeled Images" 논문 읽어봐야 쓸데 없다.
이건 AliProducts이고, 이번 챌린지는 AliProduct2이다. 구버전 데이터셋은 retrieval 언급이 전혀 없다. 전혀.
쓸데 없이 논문을 읽었다. ㅡㅡ
retrival쪽을 새로 조사하자
WebVision Dataset & Challenge 정보
찾아보는 이유:
AliProduct 데이터셋 논문이라고 공식 사이트에 걸려있는걸 봤는데, 본인들이 제안한 모델에 대한 설명에 초점이 맞춰져있어서 task를 이해하는데에 큰 도움이 되지 않았다.
저 모델이 WebVision challenge 2019에서 5000 class 부문에서 우승했기 때문에 실험 또한 본인들이 릴리즈한 데이터셋보다 WebVision을 중점적으로 다루는 듯 하다.
그런거면 데이터셋도 웹비전 영향을 많이 받았을 듯 해서 여기서 설명을 찾아보는것도 나쁘지 않을 듯 하기 때문.
=> 수정: 다 쓸데 없다 그냥 retrieval이나 보자. 다른 데이터 다른 task였다 ㅡㅡ
[데이터셋 종류?]
알리바바 논문 보니까 WebVision Dataset은 1.0, 2.0 버전 둘로 나뉘는 듯 한데, 또 paperswithcode 보니까 webvision-1000도 보여서 이게 뭔가 싶다. mini webvision은 또 뭔데...
확실하지 않지만 대충 이런 것 같다.
- 공식적으로는 1.0, 2.0 버전이 있음.
- 1.0은 visual concept이 1천개, 2.0은 5천개
- (paperswithcode에서는) 1.0이 클래스가 1천개니까 그냥 webvision-1000이라고 쓴 것 같음
- 1.0만 해도 이미지가 너무 많아서 mini 버전 데이터를 연구하는 사람들이 따로 만든 것 같음.
paperswithcode에 써있는 것도 그런 듯
데이터 다운로드 사이트를 보면 1.0, 2.0이 있고, 데이터 다운로드와 함께 toolkit을 제공한다.
https://data.vision.ee.ethz.ch/cvl/webvision/download.html
WebVision: Visual Understanding by Learning from Web Data
data.vision.ee.ethz.ch
[webvision 1.0]
데이터셋 구성?
- ILSVRC 2012 dataset의 1000가지 concept (클래스 말하는 듯)을 가지고 구글과 Flickr에 쿼리를 날려 이미지를 크롤링 해왔다. 그렇게 240만장 이상을 모은 데이터셋.
- Validation Set의 경우, 카테고리 당 50장의 이미지가 있어 총 5만장의 이미지가 있다.
- 또한 textual information도 meta 정보로서 주어진다. (caption, user tags, or description)
- train set은 human annotation이 없고, valid, text은 사람이 어노테이션을 했다.
- Task: image classification (retrieval이 아니다. 그냥 단순하게 생각하자)
이미지가 주어지면 모델 prediction 결과로서 top-5 label을 제출한다. validation set을 평가할때 top-5 accuracy 사용하는 듯.
알리바바에서 헷갈리는게 모델 학습할때 query로 날렸던 그 '클래스 이름'이 아니라 textual information만 사용 가능한건지, 그리고 validation시에도 마찬가지로 (고정된 5만가지의 클래스명이 아닌) textual information을 input으로 받아서 이미지를 찾는건지이다.
webvision 공식 웹사이트에 챌린지 떠있는건 전부 classification이다. image, video 각각이 있다.
[webvision 2.0]
- 클래스: 원래 1천가지에다가 ImageNet의 synsets에 해당하는 4천가지를 더함
- train data 1600만장, validation data 25만장 (클래스 당 최대 50장으로 구성)
- task 똑같은 듯
https://github.com/qinenergy/webvision-2.0-benchmarks
GitHub - qinenergy/webvision-2.0-benchmarks: [CVPR20 Workshop Challenge] Benchmarking image classification models for Webvision
[CVPR20 Workshop Challenge] Benchmarking image classification models for Webvision Dataset: training from 16 million noisy images from the web. - GitHub - qinenergy/webvision-2.0-benchmarks: [CVPR...
github.com
[추가]
알리바바 논문에서 자랑하는 1등 결과. https://data.vision.ee.ethz.ch/cvl/webvision/2019/challenge_results.html
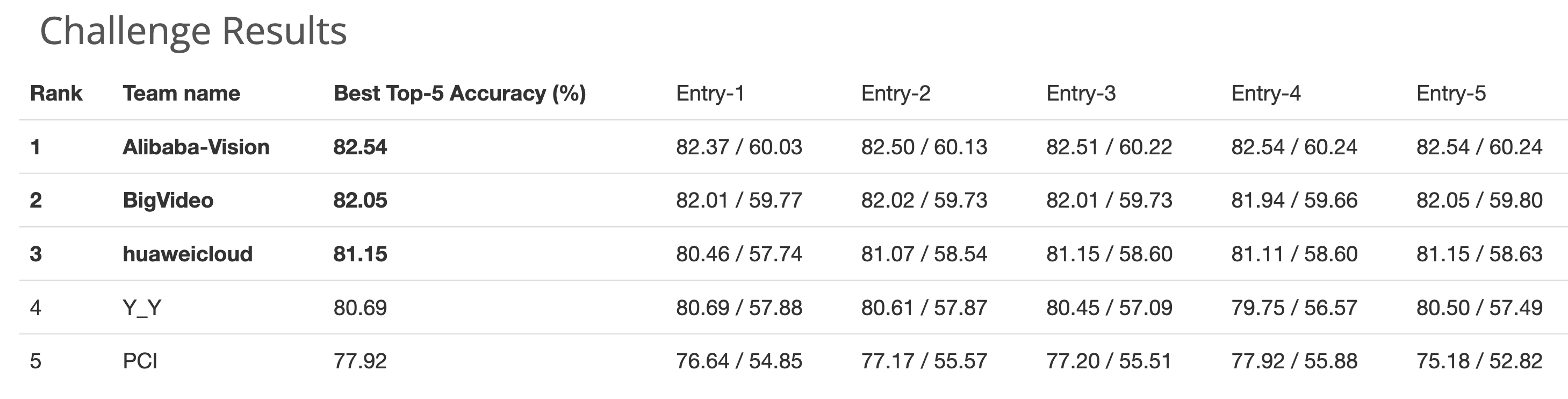
paperswithcode를 보면 SOTA 모델들이 나온다.
근데 WebVision은 classification이라서 딱히 볼 필요는 없을 듯 하다.
https://paperswithcode.com/dataset/webvision-database
Papers with Code - WebVision Dataset
The WebVision dataset is designed to facilitate the research on learning visual representation from noisy web data. It is a large scale web images dataset that contains more than 2.4 million of images crawled from the Flickr website and Google Images searc
paperswithcode.com
Image Retrieval 조사
Flicker30K dataset을 주로 쓰는 것으로 보인다.
https://paperswithcode.com/task/image-retrieval
Papers with Code - Image Retrieval
Image retrieval systems aim to find similar images to a query image among an image dataset. <span style="color:grey; opacity: 0.6">( Image credit: [DELF](https://github.com/tensorflow/models/tree/master/research/delf) )</span>
paperswithcode.com
paperswithcode 기준 SOTA는 이것
https://arxiv.org/pdf/2111.08276v2.pdf
Image Retrival로는 올해 처음 열린 듯 싶고, AliProducts2 데이터셋 논문은 없으니 (구버전 뿐임, 완전 다른 태스크) 1. 이 데이터셋에 대해 그냥 코드 구현 새로 해야하고 2. 이전 챌린지 참고자료는 없으니 그냥 image retrival 조사를 열심히 하자
끝.
retrival 보러갑니다
'다양한 취미가 있지요 > 네크로맨서' 카테고리의 다른 글
| [삽질을 해요] Weakly Supervised Learning with Side Information for Noisy Labeled Images 읽음 (0) | 2022.04.25 |
|---|---|
| 식목일 그 다음날 (싱고니움 수경재배 시작, 히아신스 꽃 핌) (0) | 2022.04.06 |
| 식목일: 초록이를 키워요 (feat. 으아악) (0) | 2022.04.05 |



댓글