최근 CVPR 2020 oral paper 위주로 서베이를 진행중인데, 그중에서 ML architecture & formulation 분야에 해당하는 논문이다.
google research에서 나온 논문.
논문 읽는 목표?
- Batch Normalization 맨날 쓰기만 했지 잘 모른다. 관련 연구는 하나도 모르고.
- 수식까지 잘 이해할 수 있을거라고 기대하진 않음. 최소한 여기 연구 동향이 어떤지 구경하자는 가벼운 마음으로 접했다.
Abstract
우선, Batch Normalization은 mini-batch단위의 statistics을 이용하여 activation을 normalize하는 기법이다. 당연히 전체 데이터의 statistics 반영 못하니까 가급적 큰 배치가 필요하고, 그게 힘드니까 문제인것.
이를 해결하기 위한 기법들로는 Group Normalization (GN), Batch Renormalization 등이 있다.
하지만 문제점이 있는데,
- 큰 배치에서는 BN보다 안좋다거나
- 여전히 작은 배치에서 잘 안되거나
- 모델 아키텍쳐에 artificial constraints가 생김.
FRN의 두드러지는 특징?
- normalization + activation function 결합된 방법이다!
- 모든 배치 사이즈에서 성능이 좋다고 한다.
이 성능은 ImageNet classification, COCO object detection에서 측정한 결과이다. - 각 activation channel과 batch element 각각 작용한다. 뭐 그렇다는데 이건 메서드를 보자.

Introduction
앞에 다른 논문과 비교한건 건너뛰고, 제안한 모델에 대한 설명을 봤다.
- 우선, 이 논문은 batch dependency가 전혀 없다.
이유 : batch sample의 각각의 activation channel (filter response)에 각각 독립적인 처리를 하기 때문 - 위 특징이 중요하다. 왜냐면 GPU 메모리는 한정되어있는데, 그러면 model capacity - batch size 사이에 trade-off가 있기 때문.
요즘 action recognition밖에 안해서 딴건 기억이 안난다만, 배치가 메모리를 훨씬 더 잡아먹는다. 물론 배치 사이즈를 늘리는건 학습을 빨리 끝내기 위함인게 크긴 하지만...?
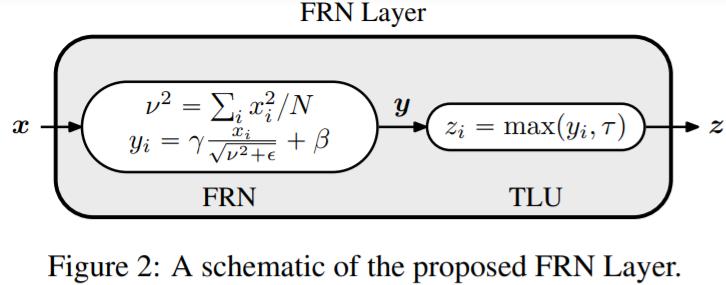
FRN layer는 두 component로 구성.
- Filter Response Normalization. (FRN)
"independently normalizes the responses of each filter for each batch element by dividing them by the square root of their uncentered second moment". mean을 빼는 연산이 필요 없음.
= per channel normalization - Thresholded Linear Unit (TLU)
"a pointwise activation that is parameterized by a learned rectification threshold, allowing for activations that are biased away from zero". 학습기반인가봄. 그래서 가능했구만.
Related Works
BN이야 그냥 mean var가지고 normalization하는 기법. 첫 문단에서는 이에 대한 간략한 설명이 나옴. 크게 어려운 내용 없어서 패스.
Methods reducing train-test discrepancy in batch normalization
이건 생각해본적 없는데. 이걸 해결하기 위한 방법 2가지를 소개했다. 먼저 BR (Batch Renormalization)은 mini-batch moments를 특정 범위로 제한해서, 미니 배치의 statistics가 크게 바뀌지 않도록 강제하였음. 그리고 EvalNorm에서는 evaluation time에 normalization statistics를 조정함. 이거 말고도 다른 방법 소개 더 했는데, 얘는 GPU 많이 든대서 패스.
Methods avoiding normalization using mini-batches.
mini-batch statistics를 사용하지 않는 방법들이 있다. 하나의 sample을 가지고 하는 등의 기법.
LN (Layer Normalization) : 이건 사용하는 논문을 많이 봤다. 전체 layer에서 normalization statistics를 뽑아 사용하는 기법. 모든 activation channels를 사용하는 것이다.
IN (Instance Normalization) : 이건 BN처럼 channel 각각을 independent하게 처리하지만, BN은 배치 전체를 쓰지만 이건 샘플 하나를 쓴다. 이게 style transfer에서는 좋은데 recognition에서는 좋지 못한 기법이었다고.
GN (Group Normalization) : 채널들에 그룹 지어서 하는 것임. 이게 특이한게 작은 배치에선 괜찮은데, 배치 사이즈가 커지면 별로였음.
그 외 기법들

Approach
여기서 다루는건 Feed-forward CNN이라는 전제가 붙는다.
4D tensor X = [B H W C].
N = W * H

1. 위 수식으로 mean squared norm을 사용하여 normalizaion 한다. N=W*H니까 채널 각각 다 다르다는 소리.
2. 그리고나서 affine transform을 할건데, 이 파라미터가 learnable하다.

3. 이 다음에 activation이 붙는다. ReLU 대신에 마찬가지로 learned threshold 사용한 TLU 사용.

이래가지고 원래 ReLU 전후로 bias를 보존하도록 하려는 생각에서 이렇게 고안을 한 것 같은데, 실제로 learned 값 뽑아보니까 전후로 다르긴 했다고함.
이 다음부터는 gradient를 보자. 수식은 언제나 보다가 포기할까봐 무섭다!
이 논문에서는 채널 각각에 대해 연산을 했으니 per-channel gradient를 설명했다고 함.
f(z)가 우리의 최종 연산결과니까, gradient는 이 f를 z로 편미분 해야할 것.
그리고 위에서 learnable parameter 3개 있었는데, 전부 channel 각각에 하나씩 있으니 여기서는 스칼라값 1개임.



이 값은 그냥 편미분 해보면 비슷하게 얻을 수 있어서 패스.
논문에서 입실론값도 학습할수 있게 해봤다고 한다.
그리고 각각 activation 채널 평균가지고 mean centering하는 등의 기법을 사용하지 않았는데, 그래서 biased될 수 있다는 단점은 있으나 TLU를 씀으로써 해소된다고 한다.
Experiment
ImageNet Classification
8 GPUs 사용, 30만 steps.

그 외에 ablation study에서 TLU가 중요하다는 점이라든가, 이 논문의 기법이 detection에서도 좋았다던가 등의 실험결과가 있지만 그렇게까지 흥미를 못느껴서 생략했다. 끝.
'AIML 분야 > 다른 연구 분야' 카테고리의 다른 글
| [서베이 & ideation] Scene Text Recognition (OCR) + Visual Feature로 representation learning을 한다? (0) | 2022.10.06 |
|---|---|
| NVAE: A Deep Hierarchical Variational Autoencoder 읽기 (0) | 2021.03.10 |
| Implicit Regularization in Tensor Factorization (0) | 2021.03.04 |
| [20201223] Journal Club - DL based multi-organ segmentation (0) | 2020.12.23 |
| Cosine Annealing 사용해보는 기록 (0) | 2020.12.04 |


댓글