커리큘럼 찾아서 똑같이 공부하면 되지 않을까
2022, 2023에 강의가 있는 CMU의 learning3d 자료가 좋아보여서 가져왔다.
슬라이드가 모두 나온 2022 버전으로 썼는데, 2023에서 논문 걸어둔게 달라졌을수도 있어서 참고해보자.
learning3d Syllabus
- Introduction
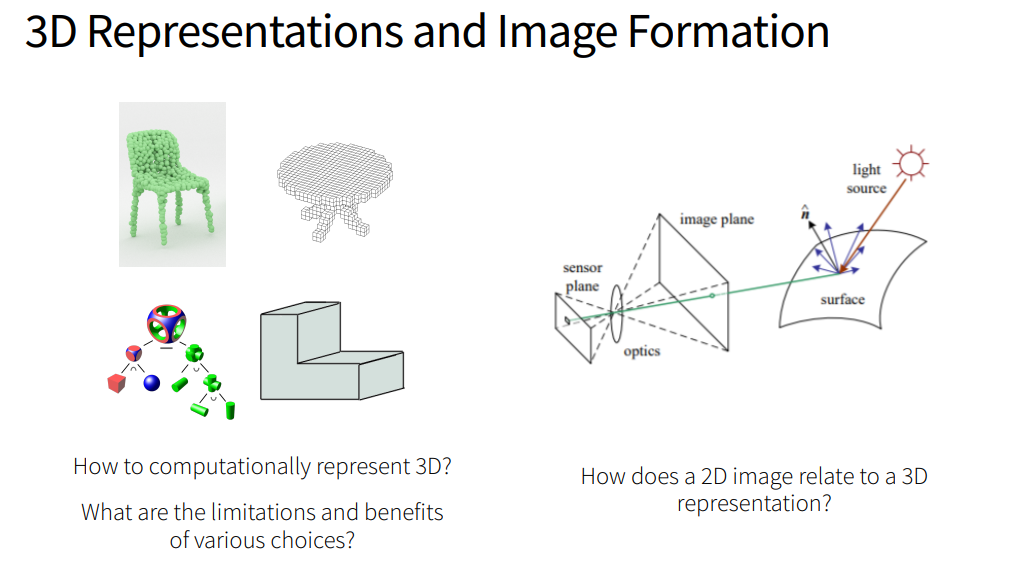
- 3D Representations
- 3D Representations: Conversions
- Image Formation
- Single-view 3D: History + 2.5D
- PyTorch3D Tutorial
- Single-view 3D: Objects
- Single-view 3D: Objects and Scenes
- 3D Prediction without 3D Supervision
- Single-view 3D: Humans and Animals
- Volume Rendering
- Neural Radiance Fields
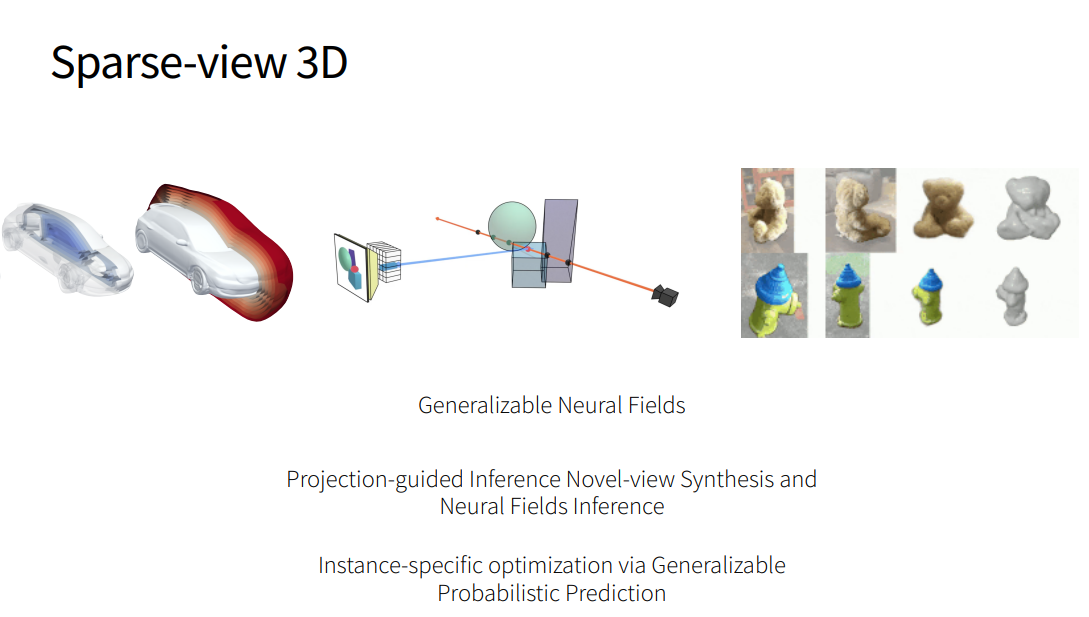
- Generalizable Neural Fields
- Rendering Signed Distance Fields
- Neural Light Fields (Ben)
- Neural Surface Rendering (Jason)
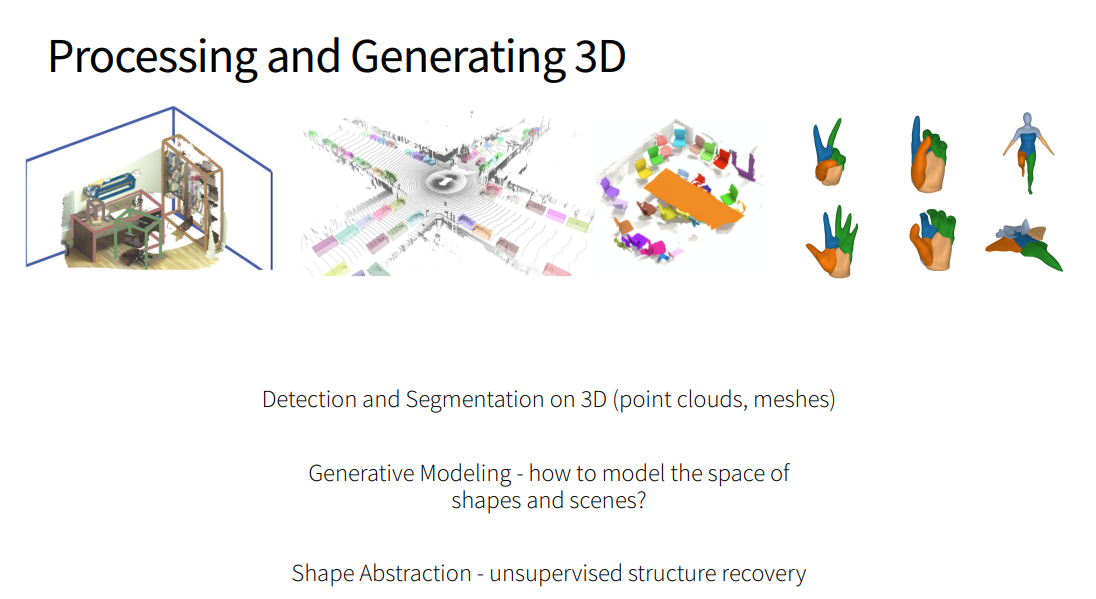
- Point Clouds: Classification and Segmentation
- Point Clouds: Detection
- Processing Meshes
- Shape Abstraction
- Generative 3D Models
- Modeling 3D in Time
- Applications: Graphics, Robotics, and Beyond
이렇게 되어있는데, 대충 나눠보면 이런 것 같다.
모르고 나눈거라 나중에 수정할지도 모른다.
1. 3D Representation & Conversion 관련
- 3D Representation 종류
- Image Formation
- Single View 3D: History, 2.5D, Objects, Scenes, Humans, Animals
- Torch3D Tutorial
- 3D Prediction without 3D Supervision
여기서 참고할 논문은 이렇게 걸려있다.
Depth Map Prediction from a Single Image using a Multi-Scale Deep Network
Towards Robust Monocular Depth Estimation: Mixing Datasets for Zero-shot Cross-dataset Transfer
Learning a predictable and generative vector representation for objects
Occupancy Networks: Learning 3D Reconstruction in Function Space
AtlasNet: A Papier-Mâché Approach to Learning 3D Surface Generation
Pixel2Mesh: Generating 3D Mesh Models from Single RGB Images
Semantic Scene Completion from a Single Depth Image
Factoring Shape, Pose, and Layout from the 2D Image of a 3D Scene
Total3DUnderstanding: Joint Layout, Object Pose and Mesh Reconstruction for Indoor Scenes from a Single Image
Unsupervised Learning of Depth and Ego-Motion from Video
Multi-view Supervision for Single-view Reconstruction via Differentiable Ray Consistency
Learning Category-Specific Mesh Reconstruction from Image Collections
SMPL: A Skinned Multi-Person Linear Model
End-to-end Recovery of Human Shape and Pose
2. 렌더링 관련
- Volume Rendering
- Neural Radiance Fields
- Generalizable Neural Fields
- Rendering Signed Distance Fields
- Neural Light Fields (Ben)
- Neural Surface Rendering (Jason)
여기서 참고할 논문은 이렇게 걸려있다.
NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis
DeepSDF: Learning Continuous Signed Distance Functions for Shape Representation
Learned Initializations for Optimizing Coordinate-Based Neural Representations
pixelNerf: Neural Radiance Fields from One or Few Images
Multiview Neural Surface Reconstruction by Disentangling Geometry and Appearance
Volume Rendering of Neural Implicit Surfaces
NeuS: Learning Neural Implicit Surfaces by Volume Rendering for Multi-view Reconstruction
Light Field Networks: Neural Scene Representations with Single-Evaluation Rendering
Learning Neural Light Fields with Ray-Space Embedding
Light Field Neural Rendering
De-rendering the World's Revolutionary Artefacts
NeRS: Neural Reflectance Surfaces for Sparse-view 3D Reconstruction in the Wild
NeROIC: Neural Rendering of Objects from Online Image Collections
3. 그 외
- Point Clouds: Classification, Segmentation, Detection
- Processing Meshes
- Shape Abstraction
- Generative 3D Models
- Modeling 3D in Time
- Applications: Graphics, Robotics, and Beyond
여기서 참고할 논문은 이렇게 걸려있다.
PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation
Vector Neurons: A General Framework for SO(3)-Equivariant Networks
4D Spatio-Temporal ConvNets: Minkowski Convolutional Neural Networks
Frustum PointNets for 3D Object Detection from RGB-D Data
PointPillars: Fast Encoders for Object Detection from Point Clouds
ImVoteNet: Boosting 3D Object Detection in Point Clouds with Image Votes
SyncSpecCNN: Synchronized Spectral CNN for 3D Shape Segmentation
MeshCNN: A Network with an Edge
Learning Shape Abstractions by Assembling Volumetric Primitives
Superquadrics Revisited: Learning 3D Shape Parsing beyond Cuboids
Neural Parts: Learning Expressive 3D Shape Abstractions with Invertible Neural Networks
Learning a Probabilistic Latent Space of Object Shapes via 3D Generative-Adversarial Modeling
pi-GAN: Periodic Implicit Generative Adversarial Networks for 3D-Aware Image Synthesis
GIRAFFE: Representing Scenes as Compositional Generative Neural Feature Fields
Neural Scene Flow Fields for Space-Time View Synthesis of Dynamic Scenes
Nerfies: Deformable Neural Radiance Fields
Cognitive Mapping and Planning for Visual Navigation
Where2Act: From Pixels to Actions for Articulated 3D Objects
이제 여기서 이미 아는 논문과 모르는 논문을 나눠보고, 각 강의 슬라이드를 대략 훑어보자.
보면서 모르는 부분 중에서 강의 참고할 수 있는건 찾아보고, 없으면 그냥 없는대로 뭐...
https://www.youtube.com/watch?v=xeWrxMHId88&list=PLSpnHWTONcJ2jhuzWUCH9UXMyJt2drGKa 겹치는 부분이 있다면 이걸 보려고 한다. 한국어 자막이 있음
~ing~
슬라이드 읽기
1. Introduction
Why 3D?
- N차원으로 일반화 하면 안되냐? -> 우리는 3D 세상이라서. 더 유용한 특성들을 사용할수 있음
Why Learning?
- 일반적인 geometry만으로는 정확하지 않아서, 데이터 기반의 학습을 하려고.
아래는 이 강의에서 뭘 다룰지, 여기서 다루지 않는 분야는 무엇인지 정리되어있음.

그래서 가장 먼저 background 공부를 할 예정.



'AIML 분야 > NeRF, 3D Pose' 카테고리의 다른 글
| SMPL-X Blender Add-on Overview (0) | 2023.02.15 |
|---|---|
| 3D Pose, Motion, SMPL ... (0) | 2023.02.14 |
| [논문 리뷰] NeuMan: Neural Human Radiance Field from a Single Video (1) | 2022.12.28 |


댓글