뭐지 어쩌다 내가 NeRF를 하게된거지
암튼 그렇게됨... 읽어볼게요
전에 썼던 관련글
- GIRAFFE (CVPR 21 best) https://ambitious-posong.tistory.com/144
NeuMan: Neural Human Radiance Field from a Single Video
ECCV 2022
https://github.com/apple/ml-neuman
뭐하는 논문인가요?
10초정도의 비디오가 주어짐. 비디오는 하나이며, 카메라는 움직임이 있음.
이걸 통해서 새로운 viewpoint, 사람 포즈 등을 만들 수 있음. 악세서리나 주름같은 세세한 것도 학습할 수 있다고함.
엥? 어떻게? scene, human에 대한 NeRF 모델을 학습함.
geometry를 대략 추정하는건 기존에 있는 알고리즘 쓸건데, 이걸 통해서 만든 warping field는 observation space에서 canonical pose-independent space로 보내는 역할을 함. 말이 어려운데 그냥 우리가 human model 학습하는 공간 말하는거임.
음??
Scenario?
- Input: 비디오 영상 하나
- Task: static scene model, human model을 reconstruction 하고싶음
- Output: 사람이 새로운 포즈를 취하는 것을 렌더링 하고싶음
- 카메라는 단 하나, annotation 없음
배경
NeRF가 나온건 ECCV 2020년 논문. 그 이후로 novel view synthesis의 퀄리티가 굉장히 올라갔다고함.
첫 논문은 각기 다른 위치의 여러 장의 이미지를 가지고 그냥 static scene을 만들었음.
그리고 얼마 안가서 dynamic scene을 생성하거나 calibration되지 않은 scene을 생성할 수 있게 됨!
요즘에는 사람에 대한 NeRF 모델도 나오고 있는데, Augmented Reality (AR)을 실현하기 위해 필요한 기술일 것임. 얼른 발전해서 메타 주가 좀 올려주세요
아무튼 기술이 발전하긴 했지만 위에 적어둔 scenario는 어려움. 기존 연구를 보면 여러 제약이 있었는데, 카메라가 여러개 있어야 하거나 lightning & exposure가 일관적이거나, background가 간단해야하거나, NeRF 학습을 위한 사람 pose에 대해 annotation이 필요했음. 예를 들면, Neural Actor는 비디오가 여러 개 있어야하고, Vid2Actor는 다른건 비슷하지만 background 모델링이 안됨.
Method 요약
Step 1. 일반적으로 많이 쓰는 모델 활용해서 다음 정보들을 뽑는다.
- human pose, human shape, human masks
- camera poses, sparse scene model, depth maps
Step 2. human 및 scene model 각각을 학습한다.
- segmentation mask를 가지고 학습하는데, Step1에서 Mask RCNN으로 추정한 것 사용함.
Step 3. Depth 추정치들을 합쳐서 regularize the scene NeRF model
- depth map으로는 multi-view reconstruction, monocular depth estimation 둘다 사용함.
- Structure-from-Motion Revisited (CVPR 16)
- Boosting Monocular Depth Estimation Models to High-Resolution via Content-Adaptive MultiResolution Merging (CVPR 21)
Step 4. pose에 독립적인 canonical volume의 human NeRF model 학습함
- 통계학적인 사람 shape 및 pose 모델인 SMPL 사용함.
- SMPL 원논문 이후 나온 "Neural actor: Neural free-view synthesis of human actors with pose control" 사용함
Step 5. ROMP로부터 SMPL 추정치를 refine함.
- ROMP: Monocular, One-stage, Regression of Multiple 3D People. (ICCV 21)
근데 정확하진 않음.
그래서 SMPL 추정치와 human NeRF 모델을 jointly optimizing 할것임. (end-to-end임)
그리고 못 본 부분은 NeRF가 만들 수 없음. 그래서 error correction network 도입함.
이 error-correction network랑 SMPL 추정치도 jointly optimized.
Methods
scene, human NeRF 각각 학습한다고 했었는데, 먼저 scene NeRF부터 배움.
그리고나서 학습된 scene NeRF를 조건으로 human NeRF 학습함.

scene NeRF
기존 motion detection의 background model과 유사함.
걍 RGB값 차이가지고 NeRF 학습함. 이때 ray에 human이 없는 background만 학습해야하잖음
그래서 segmentation mask 사용해서 값이 0일때만 (사람 없음) loss 발생시킴.
근데 이전 연구 Video-NeRF에 따르면, 그냥 학습 시키면 뭔 문제 있어서 regularizer 추가하는데, 비어있어야 하는 공간에는 density가 0이 되도록 하는거임. z가 depth인데, ray상에 depth까지 놓인 점에 대해서 밀도를 전부 합친것을 regularizer로 추가한 것.


Preprocessing
DepthMap
video sequence에 COLMAP(논문 참고) 사용하여 camera poses, sparse scene model, multi-view-stereo (MVS) depth maps을 얻음
MVS depthmap은 보통 구멍이 있는 편이라, 비어있는 곳을 monocular depth estimation 모델을 통해 채워줌
D_fuse를 얻기 위해 D_MVS와 D_mono를 쓰는 것. 이때 depth scale 맞춰야한다.
둘이 각각 추정한 것으로 linear mapping을 구한 다음, mono depth값을 D_MVS의 스케일에 맞게 조정.
Human Segmentation Mask
Mask RCNN 사용해서 구함. 그리고 사람 마스크를 4%정도 팽창시켜서 사람 부분을 완전히 마스킹 할 수 있게 만듦.
Human NeRF
사람 모델을 빌드하는 것은 pose-driven하지만, 여기서 필요한건 pose에 독립적인 표현이 필요하다. 그래서 canonical space를 정의한건데, Da-pose SMPL mesh 기반이다. Da-Pose는 observation space -> canonical space로 warping 할 때 volume collision 문제에 있어 기존 T-Pose보다 낫다는 듯.
아무튼 우리는 관측한 사람(=픽셀 좌표계)을 canonical space로 옮겨야하니, ray 위에 놓인 point들을 canonical space로 옮긴다. 그런데 어떻게 canonical space에서도 ray를 따라갈 수 있게 만들지? mesh skinning을 volume warping field로 확장하는 간단한 기법을 쓴다고 한다. (이미 있는 논문)
Input
- 각 프레임 f에 3D 점들이 있음. x_f = r_f(t)
- θf: preprocessing에서 SMPL mesh 파라미터들을 프레임 f에 대해 대략 추정해놓은 것.
3D point에 mesh-based transform인 T를 적용할 것임. 어떤 T냐면, mesh위에서 가장 가까운 point로 이동하는 rigid transformation이다. x′_f = T_θf (x_f ).
그러면 canonical space로 보내준다는 T는 너무 θf에 의존적임. 정확하지 않을 수 있음.
그래서 human NeRF와 joint optimization 하는 것이다.
그리고 warping field에 오차를 보정하기 위한 error correction network도 정의했다고 하는데, MLP로 구성되어있고 위 그림에 E로 표기되어있음. 학습에만 쓸거고 validation이나 새로운 포즈 만들때는 안씀.
말이 길었는데 아무튼 observation space -> canonical space로 가는건 아래와 같다.
여기서 canonical space 하나만 가지고 모든!!! 포즈를 나타낼거라, error-correction 모델은 프레임별로 overfit되기 쉬움. 그래서 canonical volume이 더 generalization 잘된대.
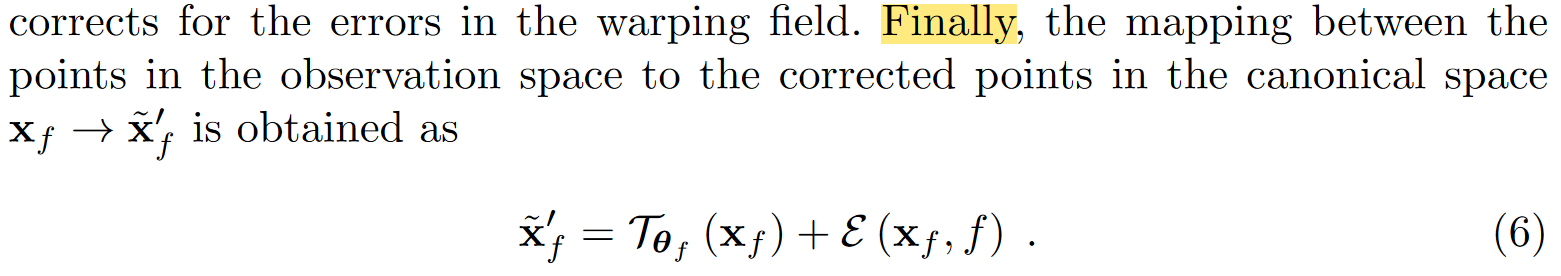
음. 근데 warping때문에 이제 ray가 휘었는데요.
previous sample이 어디에 있는지 방향을 나타내주도록 d(=viewing angle)를 저장함.
ray 따라가면서 직전 점 -> 현재 점으로 오는 방향벡터지 뭐
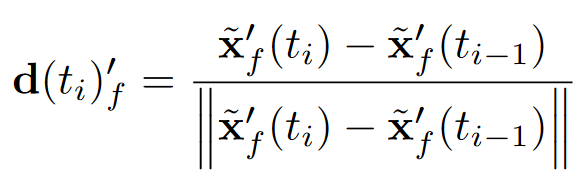
그럼 최종적으로 human model의 radiance field 값은 어떻게 정의되냐면,

pixel rendering 할때는?
2개의 ray를 쏜다. 하나는 human, 하나는 scene.
그러면 RGB와 density가 나올텐데, depth값을 기준으로 sort한다. (ST-NeRF와 비슷한 방법)
그러고나서 아래 식처럼 다 합쳐서 pixel color 구함. 그냥 NeRF 수식

학습은?
Human radiance field를 학습하기 위해서, segmentation mask에서 사람 구간에서 ray를 뽑아 학습한다.
L_{h,rgb}(r): GT RGB color와 NeRF가 구한 color의 distance를 loss로 정의.
L_{lpips}: 32*32 patch로 뭐 한다던데
L_mask(r): segmentation mask를 기준으로, 사람이 있는 곳에서의 density의 합(수식10에 alpha)이 작으면 loss를 발생시킴. alpha는 N개의 ray상에 픽셀에 대해 w_i값 합친 것! accumulated density를 의미함.
L_smpl: SMPL mesh 내부에 있으면 mesh가 solid해야하니 1에 가까워야하고, 밖에 있으면 비어있어야하니까 이에 대한 것도 loss로 줌.
L_hard, L_edge: alpha랑 w값으로 이루어진 수식에 패널티 주는데 논문 참고 ㄱ
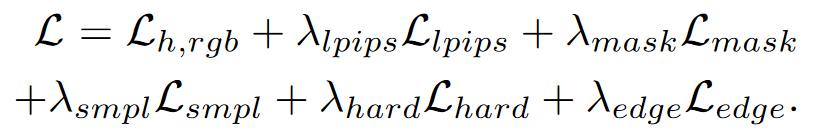
Preprocessing.
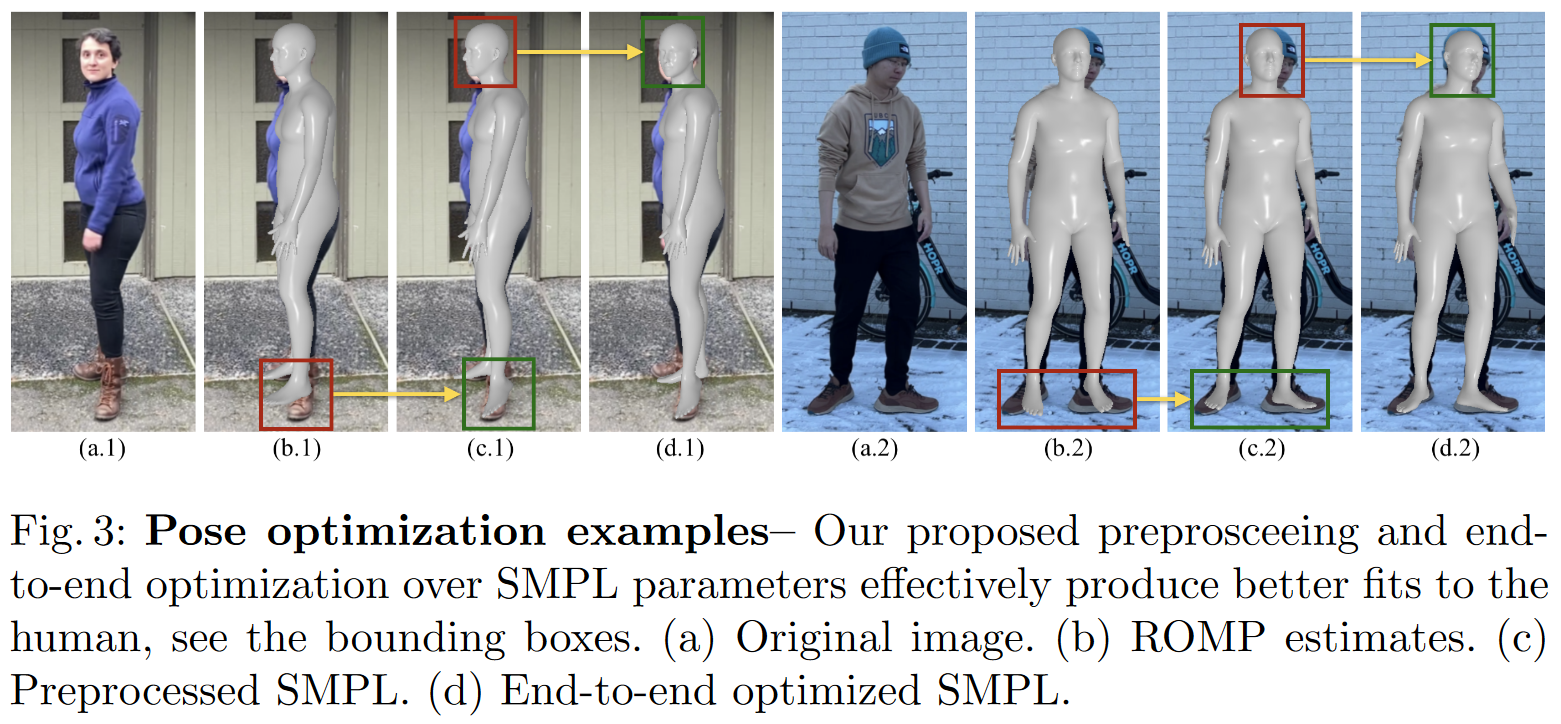
ROMP라는걸 사용하여 비디오 사람의 SMPL parameter를 추정한다.
그리고 실루엣을 사용하여 SMPL 파라미터 추정치를 업데이트 조정한다.
2D 관절도 추정한다.
그리고나서 scene 좌표계에서 SMPL 추정한다.
Scene-SMPL Alignment
PnP 문제 풀어서 3D 관절 - projection한 2D 관절 맞춤. 다만 이러면 scale을 모름.
비디오에서 적어도 한 프레임은 사람이 서있다고 가정을 함
= SMPL 모델이 바닥을 적어도 한번은 딛고있다는 가정
= feet mesh가 ground plane에 닿도록 scale 조정

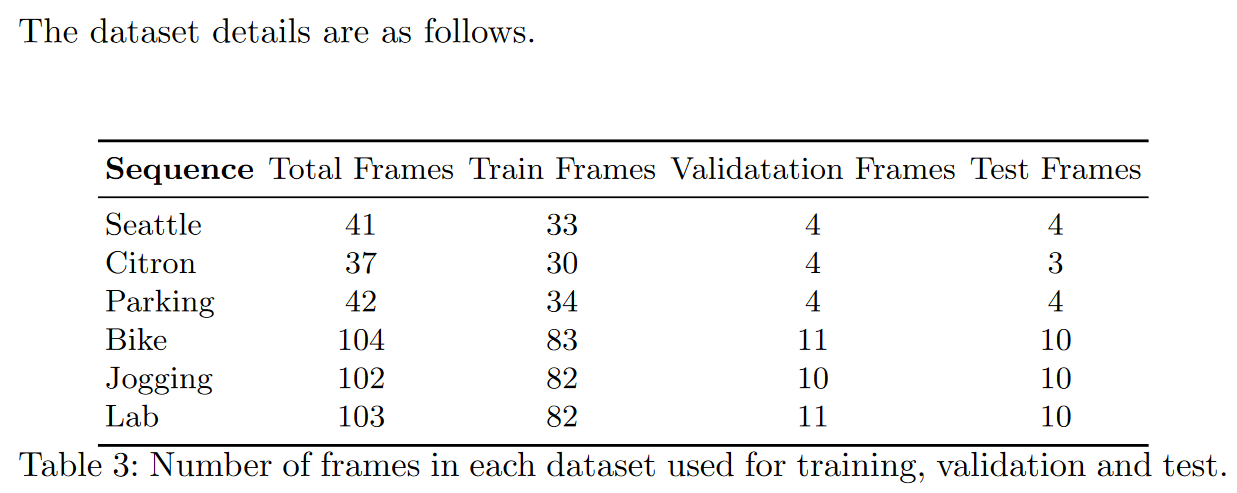
NeuMan Dataset
특징
- 6 videos about 10 to 20 seconds long each
- 6개의 각 비디오 이름: Seattle, Citron, Parking, Bike, Jogging and Lab
- single person
- performs a walking sequence captured using a mobile phone
- 각 비디오 당 프레임을 80 10 10 비율으로 나눠서 train / val / test 용도로 사용
실험 및 평가?
Scene NeRF 정성적 평가
- validation 이미지 렌더링 했을 때 dynamic한 사람을 지우고 scene rendering을 잘 하는 것을 확인할 수 있다.

human nerf 결과. 걸어다니는 동영상을 가지고 학습했는데 dynamic한 포즈도 생성할 수 있다.

그리고 모델 자체는 사람 1명으로 한거지만, telegathering이라고 해서 동작 바꾼 사람들을 같은 scene에 렌더링도 가능하다.

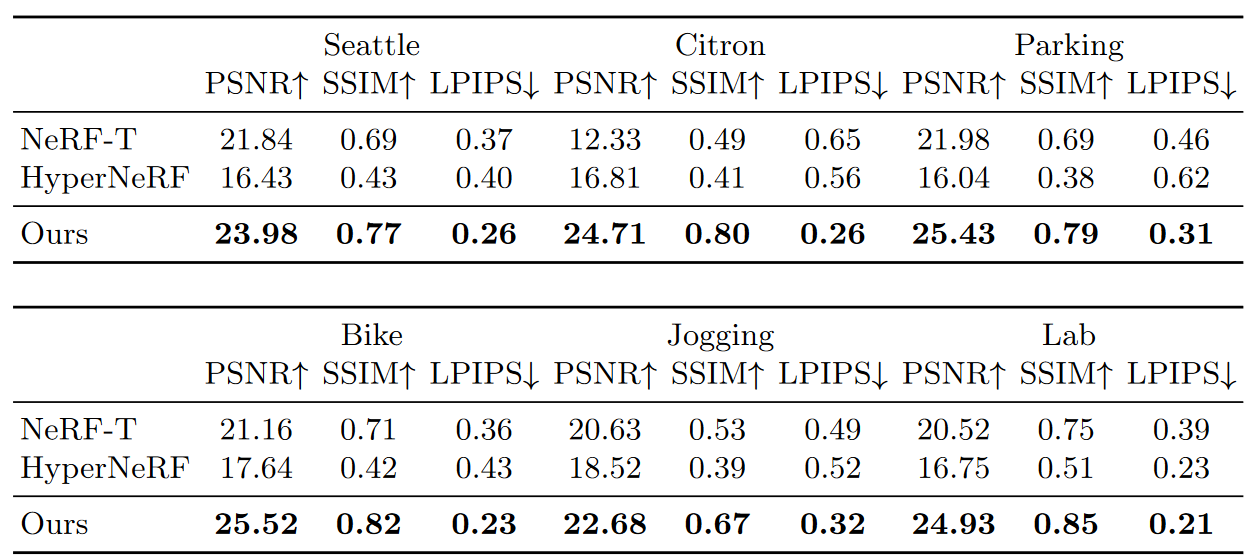
다른 모델과의 비교

근데 사람이랑 scene을 아예 따로 학습하다보니까 그림자같은건 없는듯
Novel view synthesis의 정량적 평가
ablation study는 논문 참고
논문 결론&한계에서는 바닥에 한번은 닿는다는 제약이라든가, SMPL 기반으로 하니까 SMPL에서 커버할 수 없는 손동작 등 디테일은 배울 수 없다는 것 등을 언급하고 있음.
그리고 다음에는 Structured Local Radiance Fields for Human Avatar Modeling 이거 읽을건데 (CVPR 2022)
이거는 옷 주름, 치마같은 디테일들 잘 살려서 사람 모델 렌더링 하는걸 제안함! structured local NeRF라는걸 쓴다고함
'AIML 분야 > NeRF, 3D Pose' 카테고리의 다른 글
| SMPL-X Blender Add-on Overview (0) | 2023.02.15 |
|---|---|
| NeRF 공부를 위해서 내가 뭘 모르는지 찾아보기 (1) | 2023.02.14 |
| 3D Pose, Motion, SMPL ... (0) | 2023.02.14 |


댓글