[개요]
이래저래 시행착오를 겪으며 해왔던 것을 정리하려고 한다.
의료 도메인으로 넘어오기 전에 KITTI dataset에서 미리 학습을 진행해봤었다. (AdaBins, 정상동작 확인)
SCARED Dataset을 가지고 monocular depth estimation을 진행한 결과에 정리하는 포스팅이지만 본 목적은 따로 있다.
목표로 하는 다른 데이터셋이 있는데 이게 GT가 없는데다가 영상 좌우싱크조차 잘 안 맞는 문제가 있어서, SCARED 실험을 통해
- 유사한 데이터셋에서의 toy example을 통해 분야 관련지식 습득
- SCARED로 학습한 모델을 가지고 목표 데이터셋에 knowledge transfer 하기
이러한 두가지 목적이 있다.
그래서 task를 바라보는 관점 자체가 여기에 초점이 맞춰져있다는 것을 미리 밝힌다.
그나저나 SCARED는 Intuitive에 요청하면 받을 수 있고, 챌린지로 나왔던 public dataset이니까 이글 써도 괜찮겠지?
챌린지가 끝난지 오래인 올해 arxiv에도 이 데이터셋을 사용한 연구결과가 나왔으니까.
[관련자료]
1. SCARED 공식
- 논문 https://arxiv.org/pdf/2101.01133.pdf
- 챌린지 페이지 https://endovissub2019-scared.grand-challenge.org/ (2019년)
- 전처리 코드 https://github.com/EikoLoki/MICCAI_challenge_preprocess
- 논문의 정량적 평가 metric: MSE
돼지 사체에서 얻은 데이터셋이며, 센서를 통해 depth map 정보를 취득했다는 특징을 가지고 있다.
tiff 이미지를 열어보면 몇백대의 음수값부터 양수값까지 아주 다양하게 분포되어있다.
데이터만 받으면 3채널이라 (depth값은 하나잖아요..!) 전처리 코드를 돌려줘야한다.
2. 관련 논문
- SCARED 사용한 논문1: https://www.sciencedirect.com/science/article/pii/S1361841521003479
- SCARED 사용한 논문2: https://arxiv.org/pdf/2203.02131.pdf 더 최신 논문이고, 읽기 쉬워서 이거 위주로 보는 중
관련논문을 가져온 이유는 정량적 평가를 위함
값 스케일을 모르겠어서 SCARED의 tiff 값 단위가 mm단위가 맞는지는 모르겠는데, 논문2의 성능과 비교를 해봤다.
아래부터는 각 이슈별로 진행상황을 순서대로 작성해보겠다.
Issue 1. 모델부터 정하자
Mono / Stereo? Baseline 코드는?
Monocular, Stereo 두가지 중에서 나는 monocular를 선택했었다.
사유
1. stereo는 최근 연구가 활발하지 않음. 차라리 완전히 multiview로 가서 3D Reconstruction을 하는데에 더 관심이 있음.
2. 이에반해 monocular는 최신 알고리즘들이 활발하게 나오고 있음.
3. 또한, 그렇게 최근에 나온 알고리즘의 상당수가 'Monocular Depth Estimation Toolbox'라는 open-mmlab의 mmsegmentation 기반으로 누군가가 만든 툴에서 제공함. 따라서 통일된 환경에서 비교실험을 하기가 편리함. 아예 어떤 모델들은 (depthformer, binsformer) 이 레포를 논문에서 공식코드라고 지정하고 있음.
결론
이거 씁니다.
https://github.com/zhyever/Monocular-Depth-Estimation-Toolbox
GitHub - zhyever/Monocular-Depth-Estimation-Toolbox: Monocular Depth Estimation Toolbox based on MMSegmentation.
Monocular Depth Estimation Toolbox based on MMSegmentation. - GitHub - zhyever/Monocular-Depth-Estimation-Toolbox: Monocular Depth Estimation Toolbox based on MMSegmentation.
github.com
Issue 2. GT 처리가 어려워요
tiff 이미지, 게다가 음수값의 존재
1. 코딩에러
평범한 png 파일은 아니니까 데이터 불러오는 코드들 (loading.py 등) 조금 바꿔줘야했다.
2. 어두운 값이 많음
1) 그냥 다 까맣게 나온 영역의 면적이 넓음
2) 밝은 값이 있는 영역이라고 해도 구멍이 많이 뚫려있음 -> 이렇게 비교해보니 실제보다 어두워보임
센서로 취득해서 그런건지 뭔지 모르겠는데... 아무튼 데이터셋 특징이 이렇다.
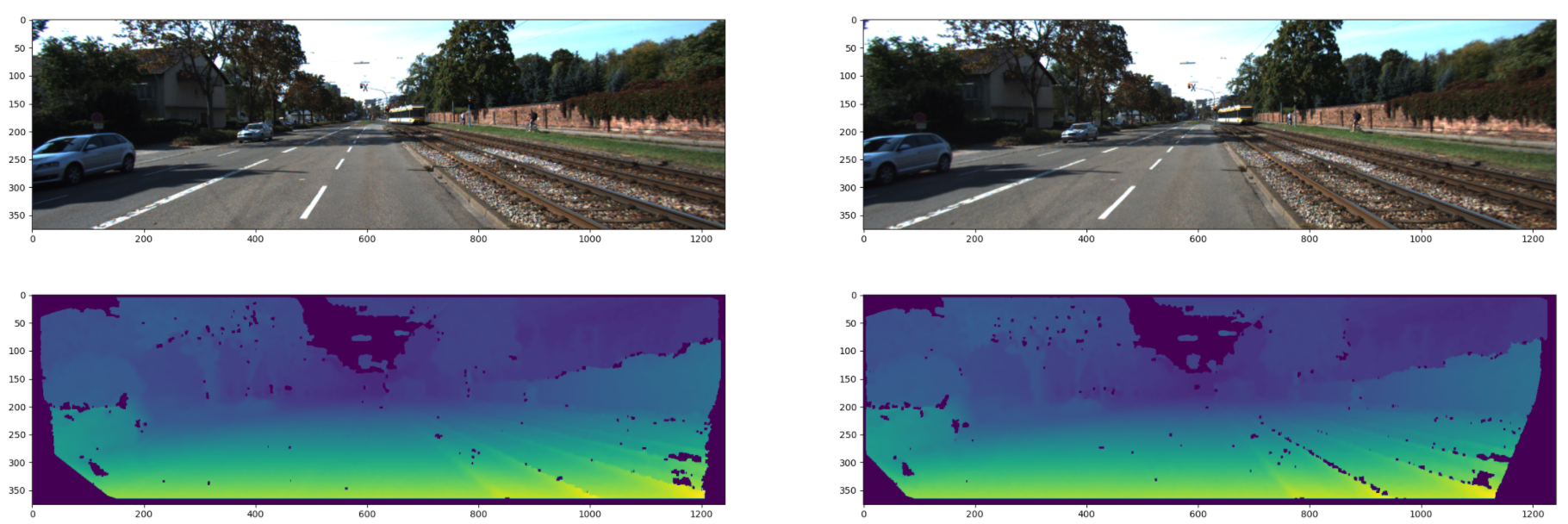
왼쪽이 GT, 가운데가 SimIPU 모델을 학습할때 pred depth이다. 오른쪽이 이미지.
pred 값이 엄청 밝아보이지만 밝은 부분 값 찍어서 비교하면 꽤 비슷할 것으로 보인다.
pred map 생각보다 잘 나오는 것 처럼 보인다.
3. 학습에 문제가 되지는 않나요? 까만게 너무 심한데
학습시에 depth의 min, max값을 지정하도록 되어있는데, 값을 넘어가면 자동으로 마스킹되게 처리되어있어서 학습하는데에는 별 무리가 없다. 다만, 이게 SigLoss() 계산할때 마스킹 하는 방식이라서 인퍼런스할때는 또 따로 처리를 해줘야할 것 같다.


Issue 3. GT가 없는 데이터는요?
(SCARED 얘기는 아니지만)
사례를 하나 찾았기 때문에 이거 위주로 설명하겠다.
저번달에 리뷰했던 Mono-depth-and-motion 논문을 보면 Hamlyn Dataset을 사용하고 있다.
그런데 이것도 GT가 없는 데이터셋이다! (그래서 꽤 참고했음)
-> Libelas라는 툴을 사용하여 pseudo GT를 생성하여 정량적 평가를 진행했다.
원래 C++ 구현이던가..? 그랬는데, 여기 보면 https://github.com/jlowenz/pyelas 사용하기 좋게 python으로 되어있다!
[참고사항]
- 'mono-depth-and-motion'에서 학습은 monodepth2의 self-supervised learning 기법을 사용했기 때문에, 학습에는 pseudo GT map을 사용하지 않았다. 정말 정량적 평가만을 위해 생성했다.
- 그럴만한게, Libelas Tool은 grayscale로 이미지를 변환해서 알고리즘적으로 매칭하는 고전기법이라 성능이 그리 좋지 않다.
- (당연하지만) Libelas는 stereo 기반이므로 좌우 이미지가 있어야합니다.
- Libelas 아닌 것도 있지만 당연히
- Libelas의 성능이 궁금하신가요? 제가 직접 뽑아왔습니다.
TMI
- 목표로 하는 성능수준이 어느정도인지 미리 정해놓자. (말이 pseudo GT이지, 구리다...)
- 성능 요구수준이 아주 높은데 monodepth로 풀겠다? 게다가 GT가 없다? 심지어 stereo video의 left-right 시간 싱크까지 안맞는다? 그런데다가 어떤 이미지가 왼쪽이고 뭐가 오른쪽인지조차 랜덤이다? -> ...
- 이 경우에서는 1) 연구기획을 다시 돌아보거나 2) 장비를 사용하여 pseudo GT를 만들도록 하거나 3) 상황은 아무것도 못바꾼다! 그냥 이 상황에서 인공지능으로 잘 해내라! 세가지 방법이 있다.
- 따라서... 현재 기획한 프로젝트에서 depth를 활용할때 어떤것을 기대하는건지, 성능수준은 어느정도 원하는지를 명확히 하여 현실적인 문제디자인을 해야 시간이 단축될 것 같다는 생각이 든다.
Issue 4. 실험 이야기
SimIPU 쓸게요 그냥
SimIPU
빠르고 적당한 성능
DepthFormer
백본으로 vision transformer를 사용하였는데, 그래서 학습시간 차이가 꽤 난다.
AdaBins
depth scale에 민감한 것 같다.
KITTI에서 잘 학습되던게 SCARED로 넘어오니 nan loss가 떠버렸다.


AdaBins 이렇게 잘되던 친구가... depthscale이 중요한거같음
BinsFormer
이 코드 첫 셋업당시에 공개 안되었는데 이제 올라왔더라. 안돌려봄. 아마 AdaBins랑 비슷할 것 같음
BTS는 아마 추가적인 정보가 있어야하는 것 같음. 역시 못돌려봄.
Issue 5. 정량적 평가
맞게 코딩한건지 아직 모르겠지만
값 스케일을 모르겠음. SCARED의 tiff 값 단위가 mm단위가 맞는지는 모른다.
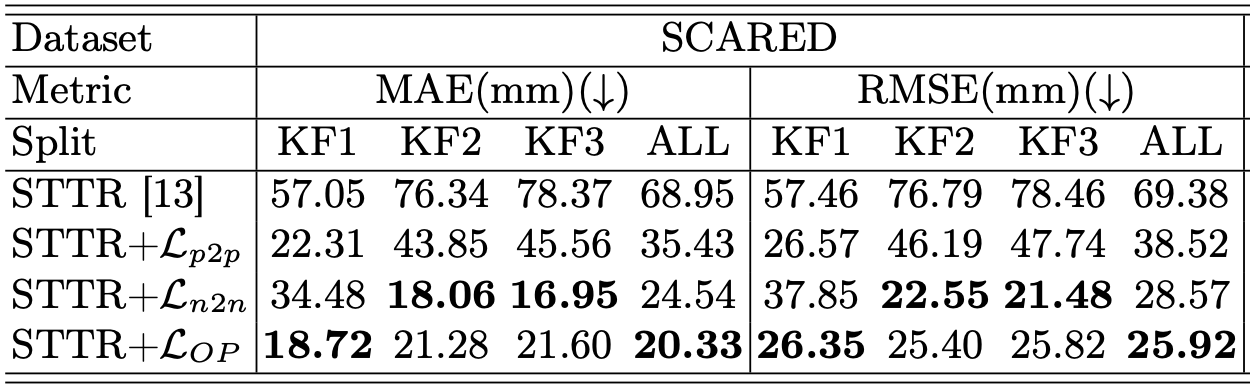
올해 논문(관련자료 논문2 참고) 기준으로 보면 이런 테이블이 있다.
STTR: ICCV 21 논문 모델, stereo라는 듯
STTR + 추가 Loss: 이 논문에서 제안한 알고리즘의 성능
SimIPU였나 DepthFormer였나.. 사용하면 RMSE 기준 44.9619 나왔음. 아마 계속 돌려보면 더 줄어들 것 같다.
작업 깃허브:
https://github.com/sghong977/SCARED_MonoDepth 코드 정리 안되어 구립니다.
의욕이 없다... 다시 mmdetection + wandb 하러갑니다.
'AIML 분야 > Depth, Camera Pose, VO, SLAM 등' 카테고리의 다른 글
| [연구일지] 2022.08.10 Monocular Depth Estimation 기록 (0) | 2022.08.10 |
|---|---|
| [Monocular Depth Estimation] mono toolbox 코드 뜯는 기록 (0) | 2022.08.05 |
| [Libelas 파이썬 버전] Depth Estimation 하는데 GT가 없을때 사용하는 툴?! (0) | 2022.07.20 |
| [Monocular Depth Estimation] Mono depth Toolbox 사용: AdaBins 돌려보기 (0) | 2022.07.19 |
| [Monocular Depth Estimation] AdaBins, BinsFormer, 그리고 KITTI Depth Dataset 셋업 (0) | 2022.07.18 |



댓글