Contents
- Intro
- BinsFormer
- AdaBins
- 셋업을 해요
Intro.
저번 포스팅에서 depth estimation에 대한 조사를 시작했다.
stereo는 다른 분께서 담당하고 계셔서 나는 Mono를 찾아보았다. 현재 SOTA는 transformer를 사용하는데다가 depth estimation을 classification-regression task로 정의한 BinsFormer이다. AdaBins도 이와 유사하게 adaptive bin을 구하도록 depth 문제에 접근했다.
따라서 나는 BinsFormer를 베이스라인으로 잡고 reproduce를 시작할 예정이나, 아직 코드가 업데이트되지 않았기 때문에 같은 레포에서 지원하면서도 유사해보이는 AdaBins를 실험할 예정이다. 그래도 기다리면 코드가 올라올테니까 두 논문 모두 살펴보려고 한다.
BinsFormer 논문은 약간 자세히 볼거고 AdaBins는 간략하게 보려고 한다.
이 두가지를 선정한 이유는,
- 둘다 depth estimation을 classification-regression task로 정의하였다. 결이 비슷한 논문이다. (저번 포스팅 참고)
- BinsFormer가 SOTA이다. AdaBins도 그에 못지 않게 괜찮은 성능을 보이는 알고리즘이다.
- git repo 하나에서 실험 가능하다. BinsFormer 저자 깃허브를 보면 AdaBins를 포함한 다른 모델들도 같이 넣어놨기 때문이다.
"BinsFormer: Revisiting Adaptive Bins for Monocular Depth Estimation"
https://arxiv.org/pdf/2204.00987v1.pdf
BinsFormer는 여러 모듈로 구성되어있는데, 아래 번호가 연산 순서를 의미하기도 한다.
1~3으로 요약해놨다.
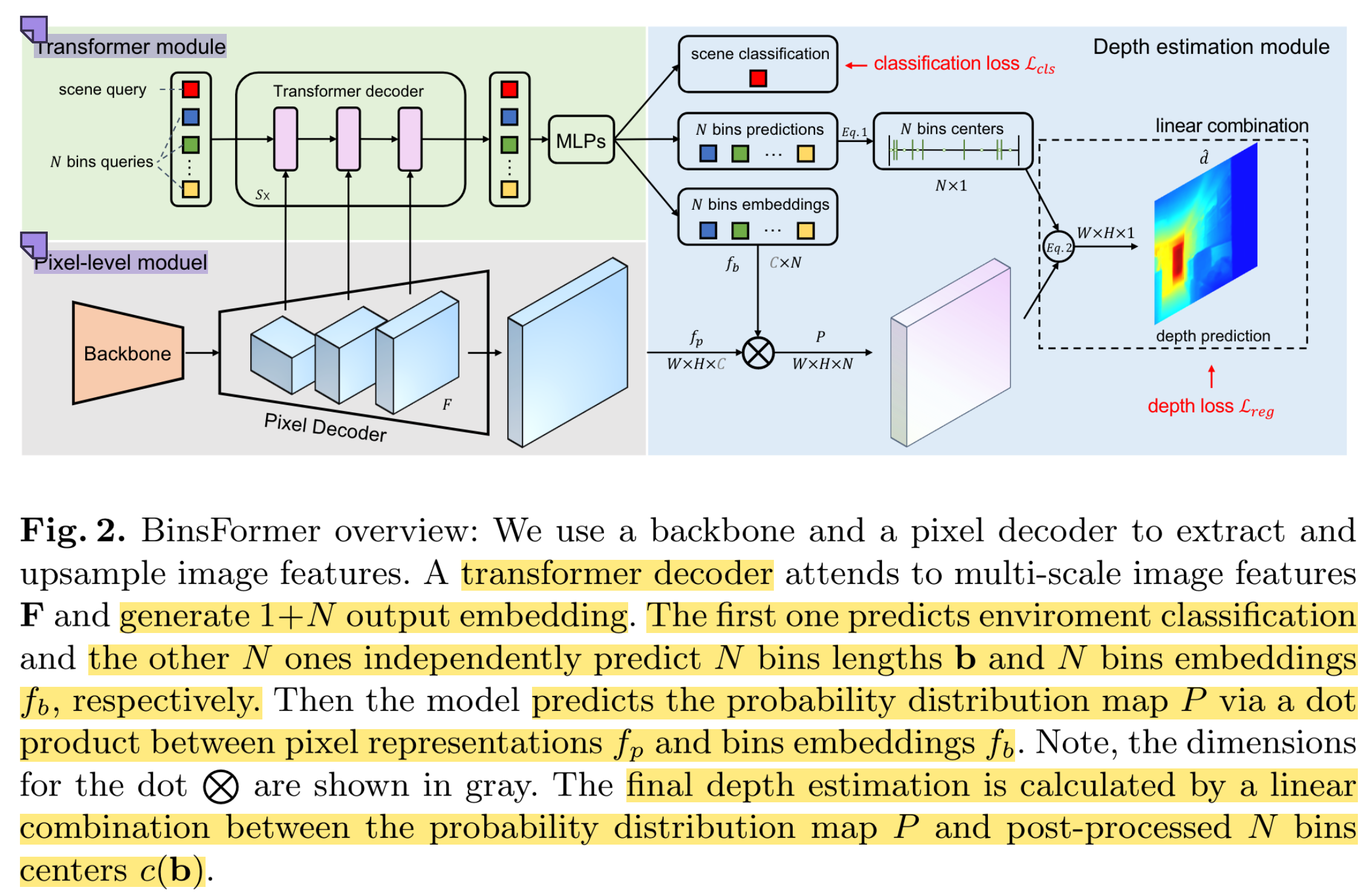
1. Pixel-level module.
여기에 RGB image를 넣고 인코더-디코더를 거친다. skip connection을 같이 활용하여 multiscale feature F를 뽑으며, 최종적으로 per-pixel 단위의 representation f_p가 나온다.
뒤에 트랜스포머 쓰는 모듈이 있다보니까 여긴 좀 가볍게 해놨더라.
2. Transformer Module.
위에 pixel level module을 거친 이후에 한다.
Transformer module은 F와 interact하여 attention mechanism을 통해 피쳐를 임베딩한다. (transformer니까요.)
또한, 독립적인 MLP들이 여러개 있는데, 얘네를 사용해서 query embedding들을 가지고 bins predictions b와 bins embeddings f_b을 만든다. bins generation을 set-to-set prediction problem의 관점에서 보면서 트랜스포머를 적용하여, global 정보를 잘 고려하면서 depth estimation을 할 수 있다고 설명한다.
추가적으로, transformer decoder를 잘 학습하기 위해서 input environment에 대해 classification task를 한다. Extra scene understanding query라고 부르더라. 그래서 transformer decoder output은 1+N개의 임베딩이다. 하나는 environment classification, 나머지 N개는 bin에 대한 embedding이다. classification에는 cross entropy loss 사용. (뭐 이것도 별도로 어노테이션이 있나봄?)
query를 어떻게 넣었고 MLP 구조는 어떻고.. 그건 이 설명 참고. 간단하게 써놨다

3. Depth Estimation Module.
마지막으로 depth estimation module에서는 위에 모듈들을 합쳐서 최종적으로 depth를 추정한다.
첫번째 것이 probability distribution P를 추정했고, 그 다음에 이걸 가지고 bin center c(b)와 함께 linear combination한다.
b는 트랜스포머 디코더 아웃풋. c(b_i)는 i번째 bin의 center이다.
d_max, min은 사용하는 데이터셋에서 가능한 min, max depth이다.

그리고 probability distribution P는 아까 pixel-level module과 bin embedding간의 dot product을 통해 similarity를 계산해서 구한다. (f_p와 f_b의 dot product)
그 다음에 P에 softmax를 취한다.
그리고 마지막으로, 각 픽셀별로 final depth prediction을 구할건데, linear combination으로 구한다.
여기서 i는 bin이다. (N개) 오 그래서 continuous하게 나오는구나.

여기 final depth map에서 scaled version의 scale-invariant (SI) loss도 구할 수 있다.

predicted와 GT depth 차이를 logscale로 바꿔서 차이를 계산한 것
+ multi-scale?
f_1부터 f_s까지 다른 스케일.
query와 함께 f_s와 cross attention 해주고, self attention 수행 후 FFN.
transformer decoder에 들어갈때 쿼리는 0으로 init하고 positional embedding과 함께 들어감

최종 loss는 다음과 같다.
각 스케일에 대해 위에서 설명한 reg, cls loss 발생시키고 (bin output이 다르겠지) 합침. 끝!
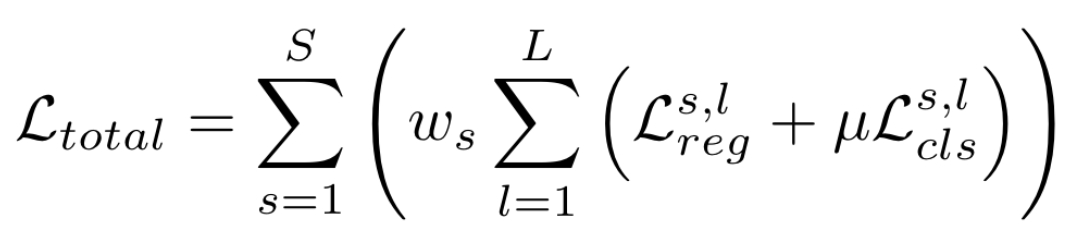
참고로, 역할별로 보여주려고 본문 그림을 저렇게 넣어놨던데 appendix가 더 와닿는다.

실제 구현에서는 뭘 써도 상관 없지만 이 논문에서는,
- Backbone: ResNet-{18, 50}, Swin Transformer
- Pixel Decoder: FPN network를 기반으로한 light-weight pixel decoder 사용
- ASPP, CBAM같은걸 활용할 수도 있다고한다. (deeplab 생각이 나네요)
하지만 transformer 쪽에서 딥하게 만들었으니까 per-pixel module에서는 computation을 다소 간단하게 했다고 한다. - "Per-pixel classification is not all you need for semantic segmentation." 논문과 같은 방식이라고 한다. 거봐. 이 분야 너무 semantic segmentation 삘이 난다니깐.
- ASPP, CBAM같은걸 활용할 수도 있다고한다. (deeplab 생각이 나네요)
- Transformer Decoder
- Default로 L=3 transformer layers, 64 queries. (single layer decoder로도 실험해보긴 했음)
- auxiliary loss는 transformer 중간 decoder layer 모두 각각에서 발생시킴
이렇게 사용했다.
Experiment
KITTI
- provides stereo images and corresponding 3D laser scans of outdoor scenes captured by equipment mounted on a moving vehicle
- 26K images from the left view for training / 697 frames for testing
- official benchmark split: 72K training data / 6K selected validation data / 500 test data without the ground truth
NYU-Depth-v2
- provides images and depth maps for different indoor scenes
- train: 50K RGB-Depth pairs subset / evaluate 위해서는 pre-defined center cropping 사용
SUN RGB-D
- an indoor dataset consisting of around 10K images with high scene diversity collected with four different sensors
- depth upper bound is set to 10 meters
- Notably, this dataset is only for evaluation. We do not train on this dataset. (NYU로 학습한거 가지고 이 데이터셋의 5050장 이미지에 테스트하여 generalization 성능 봄)
Evaluation
For the NYU Depth V2, the KITTI Eigen split datasets, and the SUN RGBD dataset,
- accuracy under the threshold (δi < 1.25i, i = 1, 2, 3)
- mean absolute relative error (AbsRel)
- mean squared relative error (SqRel)
- root mean squared error (RMSE)
- root mean squared log error (RMSElog)
- mean log10 error (log10)
KITTI depth prediction benchmark
- scale-invariant logarithmic error (SILog)
- percentage of AbsRel and SqRel (absErrorRel, sqErrorRel)
- root mean squared error of the inverse depth (iRMSE)
Details.

Results?
AdaBins도 좋아보임.



다른 데이터들도 성능 좋으니 넘어감.
Ablation도 했다. AdaBins는 bin query와 멀티스케일이 없구나.
Reg. Baseline이 Transformer도 없고 depth estimation도 없이 그냥 per-pixel depth prediction을 바로 하도록 한거란다. 성능 차이가 생각만큼 엄청나게 나지는 않는 듯..?
Baseline+는 depth estimation 모듈 없음. depth module이라고 해봐야 아까 그림에서처럼 뭐 곱하고 center 구하고 linear regression하고 그거. 다시 말해, BinsFormer와 Baseline+의 차이는 formulation밖에 다른 게 없다. regression vs regression-classification. Baseline+는 쿼리 임베딩 MLP가지고 regression 했다. 이게 벌써 AdaBins보다 성능 좋은거 보면 그냥 transformer decoder가 좋은거라는 생각도 든다. (Bins Query + Multi-S만 해도 성능이 거의 BinsFormer처럼 나올 것 같은건 기분탓?)

아 그리고 Table 6에 query bin N 개수도 다르게 실험했는데, 1~512 전부 큰 차이는 딱히 안 보이는 것 같다.
그래도 64가 가장 좋았는데, 각각의 bin이 뭘 담당하고 있는지는 visualization에서 볼 수 있다.
query 8은 가까운 것, query 64는 가장 먼 depth를 담당하고 있는걸 확인할 수 있었다.

또한 multiscale에 대한 분석도 있다.
어떻게 depth가 다르게 나오며 attention map이 어떻게 뽑히는지.


너무 최근 논문이라 아직 학회 어디붙었는지 얘기가 없는데, 이거 CVPR같은거 붙을거같은데.

AdaBins: Depth Estimation using Adaptive Bins
https://arxiv.org/pdf/2011.14141v1.pdf
dd
작성중
KITTI Dataset의 크기가 적당하다는 것을 이전 포스팅에서 확인하였으며 BinsFormer가 올라올 예정인 깃허브를 가지고 실험하기로 결정했었다. 여기서 어떤 데이터셋과 모델의 실험을 지원하는지 다시 확인했는데, AdaBins를 포함한 다양한 모델을 지원하며 데이터셋도 여러가지를 포함하는데 그중에 KITTI가 있음을 확인했다.
좋아. 문제 없이 진행해도 되겠다.
https://github.com/zhyever/Monocular-Depth-Estimation-Toolbox
GitHub - zhyever/Monocular-Depth-Estimation-Toolbox: Monocular Depth Estimation Toolbox based on MMSegmentation.
Monocular Depth Estimation Toolbox based on MMSegmentation. - GitHub - zhyever/Monocular-Depth-Estimation-Toolbox: Monocular Depth Estimation Toolbox based on MMSegmentation.
github.com

저번 포스팅에서 데이터셋 링크 걸어놨다. Raw Data는 이것저것 많으니까 스크립트 이용해서 다운받자. (공식 사이트에서 지원함.)
다운로드 받다가 서버 접속 끊기면 슬프니까 나는 도커에서 스크립트를 실행시켰고, wget 에러가 뜨면 wget을 도커 내에 설치해주고 실행하면 잘 된다. zip도 깔아주자.
apt update
apt install wget




댓글