논문 끝났다 끼히히힣!
다시 조사를 합니다.
Contents
- depth estimation이 뭐더라?
- paperswithcode 리스트를 보자: mono 볼게요
- BinsFormer 아주 잠깐 보기
- Dataset, Eval Metric
아주 잠깐 depth estimation이 뭐였는지 주절거리고 가자.
input RGB 이미지에 대해서 depth를 추정하는 것. 물체가 가까이 있는지 멀리 있는지에 대한 값을 픽셀레벨로 맞춰야한다.
Camera pose tracking이나 SLAM, SfM 등 3D로 가려면 이게 필수다. (아마도. 이 분야 모른다 이제 찾는중)
예를 들면 저번 포스팅에서 봤던 Mono-Depth-and-Motion 논문을 보면 3D Reconstruction이 최종 목표인데 아래와 같이 depth estimation, camera movement, 3D Reconstruction 세가지를 모두 한다. 왜냐면 depth 추정한것을 바탕으로 camera tracking 알고리즘 돌릴 때 많이 쓰고, 그렇게 얻은 camera pose 정보를 가지고 RGB 비디오와 합쳐서 3D 복원을 하기 때문이다.
(이거 논문 리뷰도 좀 지저분하게 해놨는데 나중에 수정 해야할듯...)

[Issue 1. mono? stereo?]
Mono를 쓰든 Stereo를 쓰든간에 epipolar geometry를 기반으로 하는 것 같다... 라고 생각했는데 (읽어본 첫 논문이 monodepth2였어서), stereo는 얼추 맞는 것 같은데 mono는 아닌 것 같다. 대강 살펴본걸로는 뭔가 semantic segmentation스럽다는 느낌을 받았다. (자세한건 다음 포스팅에 논문리뷰 하면서.)
그러다보니 원래 딥러닝 모델이 그렇기야 하겠지만 mono는 특히나 더 domain에 되게 특화적으로 학습되어서 (제너럴하게 epipolar geometry 기반으로 하여 배우기보다는 segmentation처럼 feature를 세세하게 잘 뽑아서 잘 맞추도록 학습하니까) generalization 잘 안 될 것 같긴 하다. 이런 것들은 같은 mono라 해도 monodepth2처럼 비디오 시퀀스 활용하여 epipolar geometry 기반으로 학습하는 것도 아닌데.
어쨌거나 나는 mono를 담당하기로 해서 stereo를 잘 모르긴 하지만, stereo도 간단하게 설명하자면 right 이미지를 left 이미지로 warp시켜서 매칭하는 loss를 가지고 학습한다. 다시 말해 다들 epipolar geometry 기반이라는거다. 모델마다 구조가 조금씩 다르거나 feature를 고전 알고리즘(SIFT SURF 등)을 통해 뽑느냐 CNN으로 뽑느냐의 차이라고 하신다.
epipolar geometry에 의하면, 원래 기본적으로 두 이미지간의 "상대적인" camera pose와 서로 매칭되는 포인트가 무엇인지 알면 3D 좌표를 복원할 수 있다. SIFT같은 feature를 뽑아서 매칭되는 키포인트 pair를 알아낸 후 그걸 기반으로 camera pose를 추정할수도 있고. 15년 이후 딥러닝 부흥시기부터 그런 keypoint들을 고전 알고리즘이 아니라 CNN 활용해서 뽑기 시작하기도 했다.
[Issue 2. GT]
일반 비전 도메인에서는 NYU, KITTI 등 당연하게 GT 데이터가 있다. 아마 센서로 측정했겠지.
그런데 주로 의료 도메인에서 문제인데, 데이터셋에서 GT를 제공하지 않는 경우가 있다.
음.. 당연하다. Endoscopy 하는데 누가 depth 센서를 달고 학습하기 좋게 내시경을 했겠어요. 이제와서 필요하니까 AI 해볼까?! 녹화 데이터 다 있는데? 하고 까봤지만 RGB 비디오 밖에 없고요...
그나마 Endoscopy는 SLAM 많이 하니까 몰라도 진짜 수술 데이터로 들어가면 있을리가 없음...
의료 도메인 접겠습니다. NLP처럼 좀 간지나는거 시켜주세요.
[Issue 3. Task를 어떻게 정의하나요]
단순하게 생각하면 pixel 단위의 regression이다. 픽셀별로 continuous한 depth값을 추정하는 것.
하지만 세상이 그리 호락호락하지 않으니 여러 방법이 있겠지요.
이 부분은 일단 BinsFormer 논문 리뷰하면서 intro, related work을 보고 써놨는데, 서베이 더 하면 추가하겠다.
per-pixel regression으로 푼 모델들
- DAV, DPT, TransDepth 등
- 잘 되어가지고 흔히 쓰이는 패러다임이 되었다함.
- 그러나 수렴이 늦는것과 불만족스러운 결과가 여전히 있었다고 함
per-pixel classification으로 푼 모델들
- 덕분에 성능이 많이 올랐다고함
- 근데 시각적으로 구렸다. 원래는 continuous한 depth인데 discrete하게 범위를 쪼개서 한거니까 discontinuity가 심해서.
per-pixel classification-regression task로 푼 모델들
- 각 픽셀에 대한 probabilistic representation을 배움. 초기 논문들은 bin center들을 uniform, log-uniform space 등으로 predefined.
- Adabins: adaptive하게 bin center를 결정. 그런데 decoder 마지막 레이어에서 바로 bin 추정을 하다보니 global information을 잘 반형하지 못했다. bin과 probabilistic representation을 예측하는게 모두 동일한 single layer feature로부터 나온거기 때문에, global information과 fine-grained 정보가 제한적.
- BinsFormer: transformer decoder가 bin length, bin embedding vector 두가지를 분리해서 연산하도록함. 이 논문을 가볍게 리뷰할거임
암튼 Epipolar geometry, depth estimation, camera pose, SfM, SLAM... 고전 알고리즘을 잘 알아야하며 거기에 수학 이론도 많은데다가 최근 transformer같은 아키텍쳐까지 버무려야해서 꽤 진입장벽이 높은 편이라 생각하는데 (왜냐면 내가 하기 싫기 때문이다 맨날 튕겨져 나감) 다들 많이 하는 것 같다.
작년에 암것도 모르면서 조사한다고 쓴 똥글이 자꾸 내 블로그 조회수 상위에 뜰때마다 눈물이 납니다. 수치플...
구글 열어서 S..L...A...M... 타닥타닥... ca..me..r..a... 이러면서 쓴 글이라 다시 열어보기도 흑역사인데. ㄱ-
다들 무슨 분야에서 하고 계시지요? 혹시 메타버스가 오고있나요? (유니티 주가좀 올려줘요)
암튼 어쩌다보니 나도 다시 봐야해서... 그래서,
paperswithcode 들어가서 depth estimation을 찾아봤다.
근데 이상하게 그냥 depth estimation보다 monocular depth estimation 카테고리 순위가 더 빡세다?!
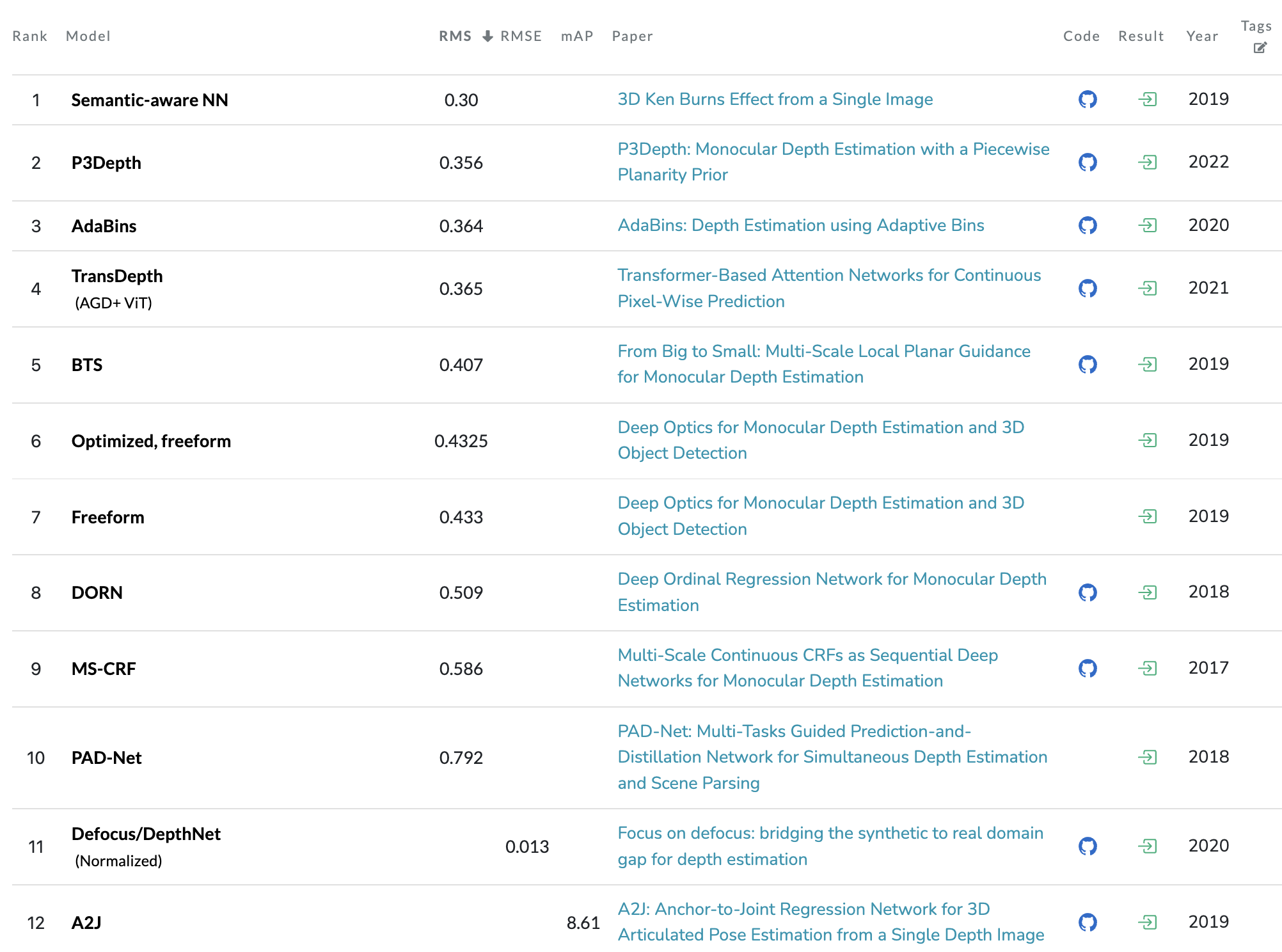
예시: NYU-Depth V2 데이터셋
https://paperswithcode.com/sota/depth-estimation-on-nyu-depth-v2
Papers with Code - NYU-Depth V2 Benchmark (Depth Estimation)
The current state-of-the-art on NYU-Depth V2 is Semantic-aware NN. See a full comparison of 12 papers with code.
paperswithcode.com
monocular depth estimation
2022년으로 기둥 세운거보소. 어이쿠 깜빡 졸았어요! 하면 모르는 논문 10개씩 생기는거다.
"이거 너무 자료도 없고 어려워요 찡찡" 했을 때 "거 자율주행에서밖에 안써서 고인물 분야입니다. 어려운거에 비해 활용이 제한적이죠" 라는 대답을 들은 게 엊그제 같은데... 여러분 진짜 대체 뭘 하느라 이렇게 depth를 열심히 하십니까?
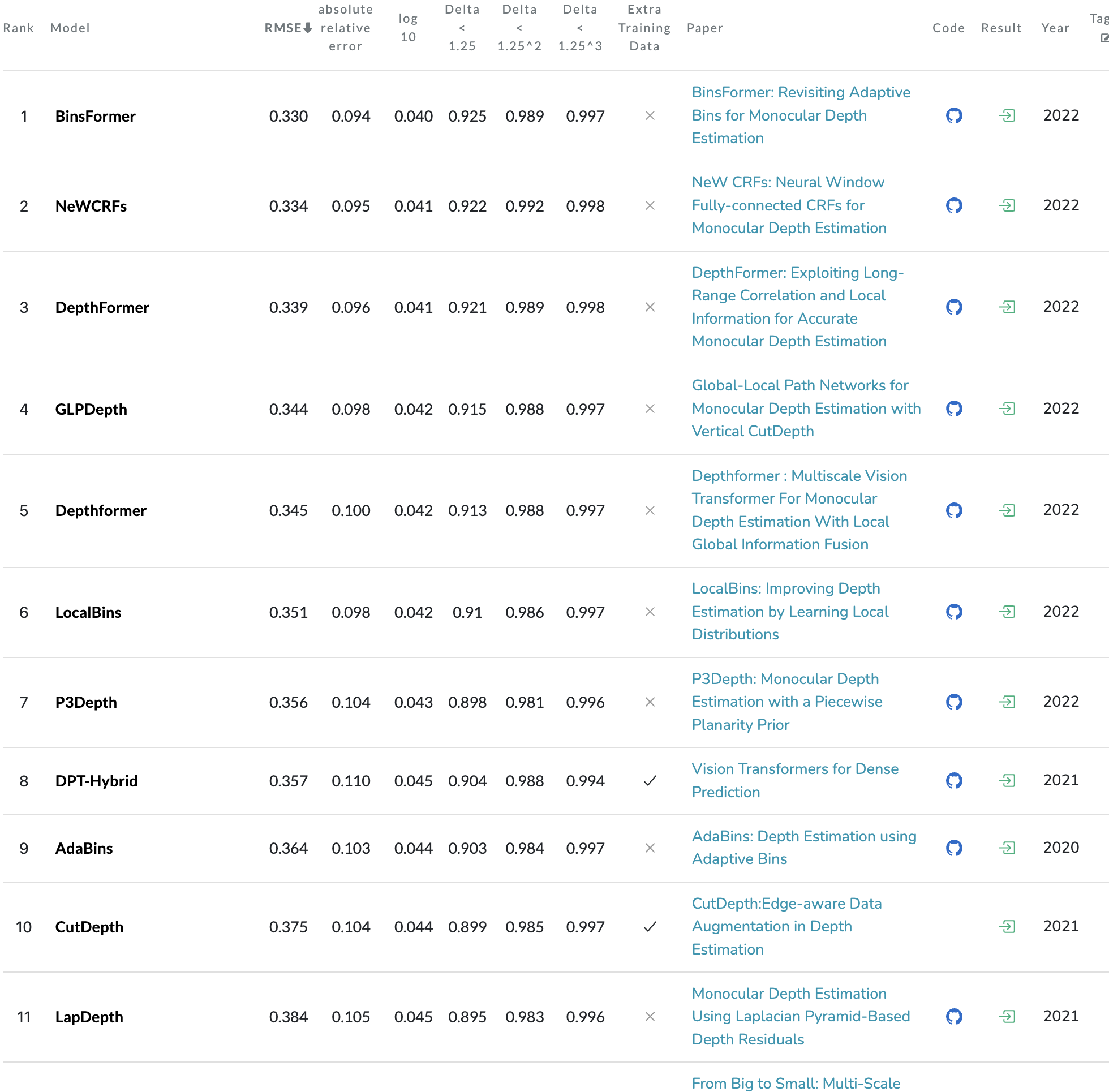
그냥 depth estimation
Stereo는 아예 페이지가 없음. 데이터셋이 이것 뿐이다.
... 그런고로 그냥 Mono 보겠습니다.
다른 분께서 조사를 잘 해주시기로 하였으니 믿습니다.
기분탓인지 중국이 많이 보입니다. 알리바바 또 본 것 같은데. (챌린지 참가 이후에 날아오는 알리바바 스팸메시지로 그닥 유쾌하지 않음)
"BinsFormer: Revisiting Adaptive Bins for Monocular Depth Estimation"
Dataset: KITTI, NYU, SUN RGB-D 사용, 압도적인 1등을 차지했다고 당당하게 말한다.
깃허브에 코드 업데이트 예정이라는데 아직 없는 것 같다.
예전 논문들의 다양한 모델이 구현되어있다.
https://github.com/zhyever/Monocular-Depth-Estimation-Toolbox
Abstract.
뭔가 요즘 메타가 바뀐건가? depth estimation task를 classification-regression task로 reformulate 하는 갈래가 있단다.
1. adaptive bins를 잘 만든다
- bin 만드는데는 transformer decoder를 사용
- spatial geometry 정보를 잘 이해하고 depth map을 coarse-to-fine으로 잘 만들기 위해서 multi-scale decoder 활용
2. probability distribution과 bin prediction간에 충분히 교류를 한다
3. extra scene understanding query: estimation accuracy를 높이기 위해 고안했는데, 뭔가 classification task를 위한 auxiliary environment가 있어서 여기서 유용한 정보들을 implicit하게 또 배운다는 것 같음
와 완전 epipolar geometry 안 쓰는 것 같음

아무튼 지금 이게 중요한게 아니라 depth estimation을 처음 본거니까, 데이터셋이나 evaluation metric같은거 알아보면서 데이터 다운받아놔야한다. 논문 리뷰는 AdaBins랑 묶어서 다음 포스팅에.
Binsformer에서 Dataset을 KITTI, NYU, SUN RGB-D 쓴다고 했고, 이 논문이 일반적인 evaluation protocol을 사용한댔으니 이거 보면 얼추 맞겠지.
Evaluation Metrics
- accuracy under the threshold (δi < 1.25i, i = 1, 2, 3)
- mean absolute relative error (AbsRel)
- mean squared relative error (SqRel)
- root mean squared error (RMSE), root mean squared log error (RMSElog) and mean log10 error (log10)
KITTI Depth.
http://www.cvlibs.net/datasets/kitti/raw_data.php Raw Data는 여기서 또 받아야한다.
The KITTI Vision Benchmark Suite
This page contains our raw data recordings, sorted by category (see menu above). So far, we included only sequences, for which we either have 3D object labels or which occur in our odometry benchmark training set. The dataset comprises the following inform
www.cvlibs.net
http://www.cvlibs.net/datasets/kitti/eval_depth.php?benchmark=depth_prediction Depth Estimation.
공식 서버에 제출한 SOTA 순위라든가 evaluation metric 등의 설명은 이 페이지를 참고하자.
The KITTI Vision Benchmark Suite
When using this dataset in your research, we will be happy if you cite us: @INPROCEEDINGS{Uhrig2017THREEDV, author = {Jonas Uhrig and Nick Schneider and Lukas Schneider and Uwe Franke and Thomas Brox and Andreas Geiger}, title = {Sparsity Invariant C
www.cvlibs.net
이것만 보고 데이터셋 크기가 작은줄 알았는데, 이건 어노테이션만 포함된다.
RGB or grayscale 프레임, calibration parameter 등 Raw Data도 추가로 다운 받아주자. (용량이 크다)

Evaluation Metric

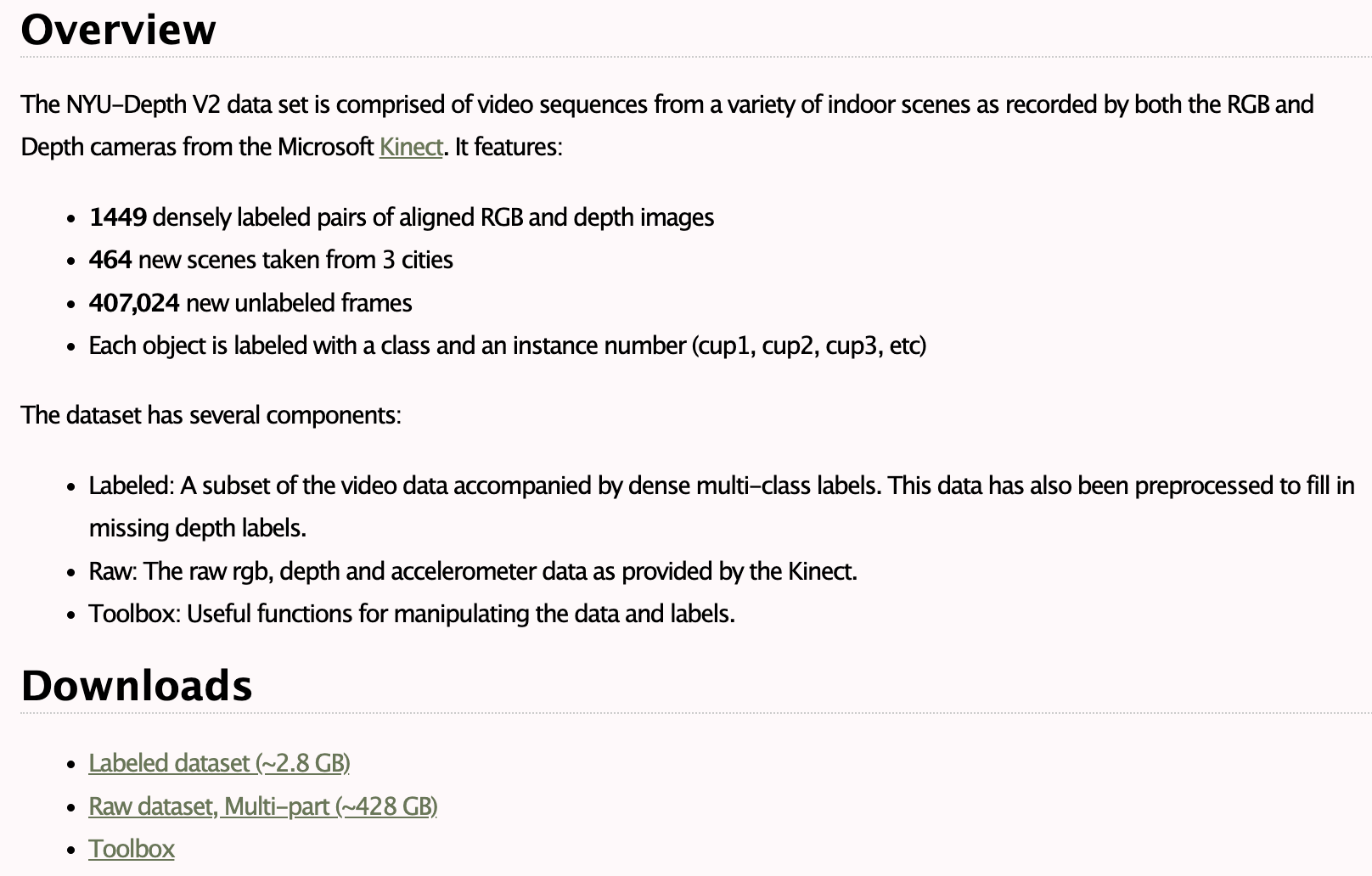
NYU Depth V2 Dataset.
링크
https://cs.nyu.edu/~silberman/datasets/nyu_depth_v2.html
indoor scene이며, Kinect depth 카메라를 사용했다.
Labeled가 dense multi-class label을 포함한다고 한다.

Raw라고 적힌건 RGB, depth, accelerometer를 제공한다고 한다. (kinect 정보) 나는 depth estimation 하는거니까 그냥 Raw를 쓰면 되는 것 같다.
그런데 용량이 428GB... 오...
SUN RGB-D
CVPR 15라고 한다.
https://rgbd.cs.princeton.edu/
SUN RGB-D: A RGB-D Scene Understanding Benchmark Suite
Although RGB-D sensors have enabled major breakthroughs for several vision tasks, such as 3D reconstruction, we haven not achieved a similar performance jump for high-level scene understanding. Perhaps one of the main reasons for this is the lack of a benc
rgbd.cs.princeton.edu
눌러보니까 이미지랑 어노테이션 합쳐도 7GB 쯤 되는 것 같다.
만약 이 데이터를 다른 논문에서도 많이 쓴다면 이걸 셋업하는게 간단한거 테스트용으로는 좋아보인다.

하지만 일단 그냥 익숙한 KITTI 다운 받아보고 생각하겠습니다.
KITTI 예전에는 사용신청 하면 이메일로 다운가능한 링크를 보내줬던걸로 기억하는데, 이제는 그냥 회원등록하면 바로 다운받을 수 있다.
하아... 미팅하고 와서 다시 해야지



댓글