논문 읽으면서 정리 + 주절주절 아무말
간지나는 논문이 나왔으니 읽어주는게 인지상정이다.
Masked Autoencoders Are Scalable Vision Learner
FAIR
AutoEncoder는?
Encoder-Decoder 형태의 아키텍쳐이며, 좋은 인코더 얻으려고 학습한다. representation learning의 관점.
디코더를 통해 input을 복원하도록 loss를 학습시키면, 핵심적인 시맨틱을 가지는 좋은 feature를 뽑도록 네트워크가 훈련될테니까.
(VAE와 비교해서 설명하는 글이 많이 있으니 모르면 찾아보도록 하자. 얘는 반대로 생성을 잘하기 위한, decoder를 얻는게 목적인 구조이다. 어쨌거나.)
Denoising Auto Encoder (DAE)도 있는데, 말그대로 input에 noise를 추가했음에도 디코더의 output은 noise를 추가하지 않은 원본을 복원하도록 하자는 아이디어이다. Autoencoder가 그냥 복붙을 해버리는 네트워크(=identity 연산)로 학습되는걸 방지하기 위한 좋은 아이디어였다.
Vision에 Transformer가 들어온 이야기
NLP에서의 transformer가 갑자기 vision계에서 흥하면서 (by. ViT. 결국 ICLR 21 되었더라), 대체 왜 트랜스포머가 비전에서 좋은지에 대해 연구를 많이들 하고 있다. 대략적으로 기억나는 연구 주제와 흐름은 아래와 같다.
- 왜 잘되는가?
attention 덕분인가? position encoding이 도움이 되는가? 도대체 이미지를 시퀀스로 보는게 무슨 의미가 있는가? - 굳이 연산량과 메모리가 quadratic한 self-attention 연산을 써야할 이유가 있나? 연산을 Linear하게 줄일 수는 없나?
- attention 연산 자체를 줄이려는 시도도 많았음. Performer 등
- swin transformer처럼 윈도우를 나눠서 연산량을 줄인 케이스도 있음
- CNN 연산과의 구조적인 차이는 뭔가? (feat. inductive bias, CNN의 locality라는 prior)
- 만약 self-attention이 CNN을 대체 가능한거라면, attention이 없는 그냥 MLP와는 어떤 차이가 있는가?
(feat. MLP Mixer, gMLP 등) - CNN의 locality는 무시할 수 없는 장점인데, 두 장점을 융합시킬수는 없는가?
- CNN은 수렴도 빠르고, 애초에 vision의 특성을 잘 반영한 연산이면서도 파라미터도 효율적이니 포기하기 어렵다!
- low level layer에서는 CNN을 써야하는 연구가 있음
- attention 주는 방식을 locality 반영할 수 있도록 바꾼 논문도 있음. 점차적으로 커널을 늘려서 global attn까지 배우게함.
- 모델 자체를 CNN과 융합한 케이스도 있음. (CMT 등...)
=> 사실 이때까지는 심드렁했다.
논문들을 읽다보면 저자의 어조에서 '굳이 CNN 대신 써야하나? 뭐가 이득이라고...' 라고 말하고 싶어하는 느낌을 받았다.
나 또한 네트워크 외적인 요인이라고 생각했던게, 최근에 데이터셋 규모가 커지고, optimizer, augmentation & regularizer, learning metric이 좋아져서 성능 높은거 아닌가 하는 생각이 들었었다.
- CNN과 다르게 두드러지는 ViT계열의 특징은 무엇인가? 사용 이점은? (feat. robustness)
- 구멍 뚫린 이미지를 넣으면 해당 부분에 attention을 줘서 추론하고, CNN대비 아주 강한 robustness를 가진다는 논문이 나왔다. 심지어 비어있는 공간까지 추론할 수 있는 능력이 있었음.
- 기존 실험 잘못되었다면서 fair comparison 할 수 있는 셋팅해놓고 다시 실험한 논문도 있는데, 그것도 결론은 transformer가 robustness 측면에서 이점을 갖는다는게 확실했다.
대략 이렇게 흘러온 것 같다. 다른 vision tasks를 해결하는 부분은 생략하고, 비전과 transformer의 관계를 고찰하는데서 나온 연구 주제만 생각나는대로 적어봤다. 어쨌거나 "transformer 구조가 장점이 있다는건 확실한데... 흠..." 상태인 듯.
NLP 이야기
여기서 더 나아가 근본적으로 NLP와 비전의 공통점과 차이점이 무엇인지에 대해서도 고민하기도 한다. 왜냐면 원래 트랜스포머는 NLP에서 나왔으니까. 그러니 NLP에 대해서도 조금 알아보도록 하자.
현재까지 가장 많이 언급되는 NLP는 GPT계열 모델(1,2,3)과 BERT다. 나는 이쪽 잘 몰랐는데, 아키텍쳐 자체는 그냥 트랜스포머 self attention을 사용하지만 학습 방법이라든가, 인코더를 쓰느냐 디코더를 쓰느냐 등 많이 나뉘더라.
GPT계열과 BERT는 각각 autoregressive language modeling, masked autoencoding이라고 불린다.
autoregressive 하다는 표현은 그냥 트랜스포머 생각하면 되는데, 디코더 단에서 현재까지의 inference output을 가지고 다시 input으로 활용하여 다음 단어를 inference한다.
BERT는 트랜스포머의 인코더 파트를 사용하며, Masked Language Modeling (MLM)을 통해 pretraining을 한다. 몇 단어를 무작위로 마스킹을 함으로써 빈칸을 잘 추론하도록 인코더를 학습하는 기법이다. 일종의 self supervised learning이기도 하면서도 autoencoder 모델이라고 할 수 있다. BERT는 수많은 downstream task에서 성공적으로 동작한다.
본론으로
GPT의 autoregressive도, BERT의 MLM도 아이디어는 같다. 일부를 가리고, 원본을 추론하여 잘 복원하도록 한다. 이건 autoencoder의 개념이다.
그 말은 즉, NLP에서는 autoencoding이 아주 잘 발전해왔는데, CNN에서는 그렇지 못하다는거다.
도대체 NLP와 Vision에는 근본적으로 어떤 차이가 있는걸까?
정보의 집약도가 다르다고 논문에서 설명한다.
언어는 단어 하나하나가 굉장히 중요하며 informative하다. 단어 하나 누락되면 의미가 달라진다.
그런데 비전의 경우, 의미없는 배경이라든가 반복적인 패턴 등의 특징을 가지고 있다. 다시 말해, 의미를 식별하기 위해 정보를 추출한다는 관점에서 보면 굉장히 information density가 낮은 신호이다.
또한 decoder의 역할이 다르다. decoder는 latent representation을 input으로 mapping하는데, NLP는 단어이지만 이미지는 픽셀을 생성한다.
픽셀은 low level semantic을 가진다. 픽셀 하나하나에 그리 큰 의미를 담고있지 않는다.
이와 다르게 NLP의 경우 단어 하나하나를 생성 하는데, 이건 담고있는 semantic level이 높다.
이러한 information density의 차이점을 관점에서, BERT의 MLM을 생각해보자.
BERT에서 학습이 가장 잘되는 optimal한 masking ratio는 15% 정도로 알려져있다. 너무 과하게 가리면 추론이 어려울테니 말이다.
이미지는 반대로 information density가 낮고 redundancy가 큰 특성을 가지는데, 동일하게 autoencoder를 만든다 생각하면 masking ratio가 더 높아야 효율적이지 않을까? redundancy가 줄어들어서 정말로 추론을 위한 semantic을 배우는 self-supervisesd learning이 가능하기 때문이다.
이 논문의 실험 결과에 따르면, 실제로 vision domain에서 optimal한 masking ratio는 무려 75% 정도라고 한다. 이미지의 25%만 보고 다른 부분을 추론하도록 학습한 모델이 인식 성능에 도움이 된다는거다.

모델 tmi
기존 ViT대비 pretraining 시간이 3배나 빠르다고 한다. 정말로 위에 말한 가설대로 추론을 잘 하도록 학습되어서 그런건지, 그냥 인코더가 작아서 그런건지는 모르겠는데, 에폭을 적게 돌린건 아니고 걍 attention 연산이 sequence length에 quadratic하기 때문이다.
심지어 네트워크는 그냥 vanilla ViT-Huge를 사용한데다가, 데이터도 ImageNet-1K만 사용했다고 한다. (JFT 안썼나봄)
그럼에도 ImageNet-1K finetuning 성능이 87.8%나 된다.
- Masking은 랜덤으로 하되, 개수는 고정.
구현할때는 random shuffle 후 마지막 부분 N개를 제거하는 식으로 한다. input의 25%만 사용한다. (mask ration 75%) - MAE Encoder: masking 했다고 말은 했지만 실제로는 mask token을 사용하지 않는다.
그대신에 안 보는 파트는 제거해버린다. 그러면 sequence length가 1/4로 감소하여 모델이 많이 작아짐과 동시에 학습 성능에도 좋다. 왜냐면 train test때 어떤건 뚫려있고 어떤건 이미지만 들어오면 모델 입장에서는 난감할테니 말이다. - MAE Decoder: full sequence로 처리한다. 이를 위해 아까 셔플했던거 inverse 계산.
encoded visual pathes + mask token.
pretraining시에만 디코더를 사용하며, downstream task에서는 사용하지 않는다. BERT처럼.
그렇기 때문에 모델을 굉장히 작게 설정했다. 인코더가 100이라고 하면, 디코더는 10도 안되는 규모이다. - Image Reconstruction Task: MSE loss로 학습, 단 마스킹된 패치에서만 계산한다. (BERT와 동일)
reconstruction target을 normalized pixel로 두면 representation 학습이 더 잘 되었다고는 하는데, 논문에서 디폴트 설정은 normalization 없는 것으로 뒀다.
Experiments
Baseline 실험.
ViT-L과 마스킹 등으로 모델 크기를 줄인 이 논문의 것과 비교한 테이블이다.
여깄는 것들은 전부 ImageNet-1K에 supervised learning을 한 결과이다.
original과 이 논문의 구현 성능 차이가 큰건 이것저것 튜닝했기 때문인데, ViT의 작은 모델에서는 잘 되는 조합을 찾는 시도가 많았지만 ViT-Large의 경우 computation 때문인지 잘 없었다고 한다. 어떤 셋팅에서는 빈번하게 NaN loss가 뜨기도 했다는데, 이 논문이 학습한 레시피의 경우 NaN 없이 잘 수렴한다고 한다.

linear probing
feature representation learning이 잘 되었는지 검증하는 방법이다.
마지막 레이어보다 중간 레이어가 좋다고 해서, 그거 빼고 뒤에 FC를 붙여서 뒷부분만 finetuning하여 classification 하는 검증방법.
self supervised learning 기법들 검증할때 많이 쓰는 방법이라고 한다. 당연히 전부 finetuning 한 것 보다는 성능이 떨어진다.
MocoV3 (ICCV21) 논문에 나온 것과 동일하게 했다고 한다.
MocoV3가 contrastive learning 하는데다가 ViT에서 실험했다고 하니 나중에 Moco 시리즈를 읽어주는걸로 하자. 진짜 할지는 모르겠지만...
그런데 linear probing 관점에서 봤을때, 성능이 MoCov3처럼 contrastive methods들에 비해서는 성능이 떨어진다. representation이 더 distingushable하기 때문인건가...
ablation study.
디폴트는 회색
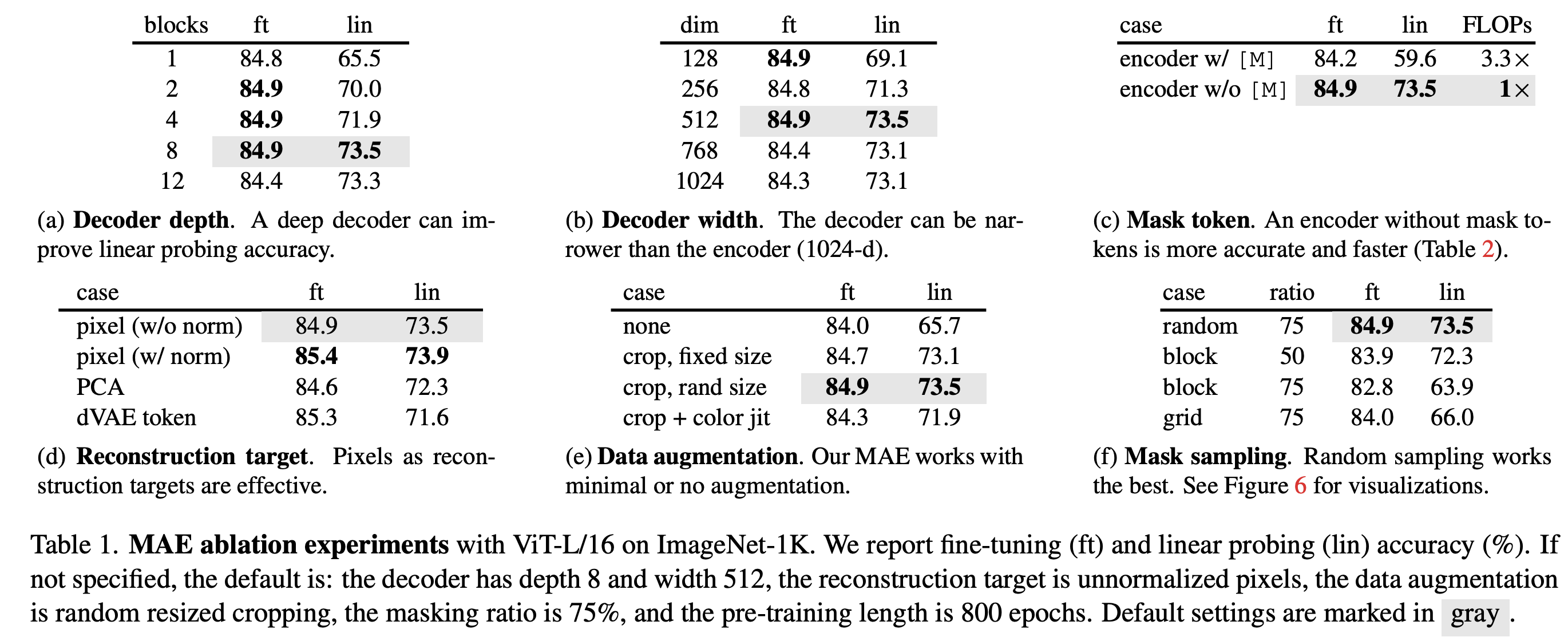
(c)에는 마스크 토큰 유무에 대한 실험이 있다. 여기서 주목할 점은 mask token 사용시에는 linear probing 성능이 매우 떨어진다는 점이다. Mask token 사용시에는 근본적으로 train/test input상에 차이가 있는데, 학습시에는 Input에 누락된 부분이 많지만 테스트에서는 마스크가 없는 이미지를 넣기 때문이다. 논문의 기본 셋팅대로 25%만 선택해 사용하는 것으로 하면 빈 공간 없이 input size 자체가 작아지는 구조이므로 train/test 상의 차이는 사라진다. 이로인해 representation 측면상에서 차이가 발생함을 실험 결과를 통해 보여준다.
(d)에는 reconstruction target에 대한 실험이 있다. target pixel을 normalization한 것과 그냥 이미지를 가지고 MSE를 구한 것의 차이를 보면, normalization을 적용한 것을 target 삼는 것이 학습에 더 도움이 된다. 또한 patch space에서 PCA를 적용한 후 largest PCA coefficient(96개)를 사용한 실험도 있다. 하지만 이 경우에 성능이 감소했는데, 그 얘기는 high frequency 정보가 중요하다는 얘기가 된다. tokenizer로서 pretrained dVAE를 사용한 것도 있는데, normalization 없는 경우에는 이를 통해 성능증가를 얻었지만 normalization이 있을 경우에는 이득이 없다. pixel-based MAE가 더 단순하고 overhead도 무시할만한 수준이기 때문에 dVAE를 여기선 굳이 쓸 이유가 없어보인다.
(e) augmentation을 빡세게 주지 않아도 괜찮은 듯 하다. 이 논문에서 말하길, 다른 self-supervised learning 기법은 data augmentation 기법에 매우 의존적인데 이 논문(MAE)은 그렇지 않다고 말한다.
(f) 마스크 샘플링 방법에 대한 ablation을 보면 랜덤이 가장 좋았는데, block단위로 없애버리면 성능이 상당히 나쁜 것 같다.
여담인데, 그러면 cutout같은 augmentation 기법도 원논문처럼 적용할 게 아니라 작은 패치를 랜덤하게 많이 발생시켜서 없애는 방식으로 적용하는게 성능이 더 좋지 않을까 싶은 생각이 든다.

800 에폭 pretrain.
MoCo V3의 경우는 300에폭만에 saturation이 있는데, 이 모델은 1600에폭을 돌려도 성능이 오른다.
아무래도 모델이 이미지의 25%만 보는 것과 200%(mocov3 2 crop 기준) 보는건 정보의 양 자체가 다를테니 그럴 수 밖에.
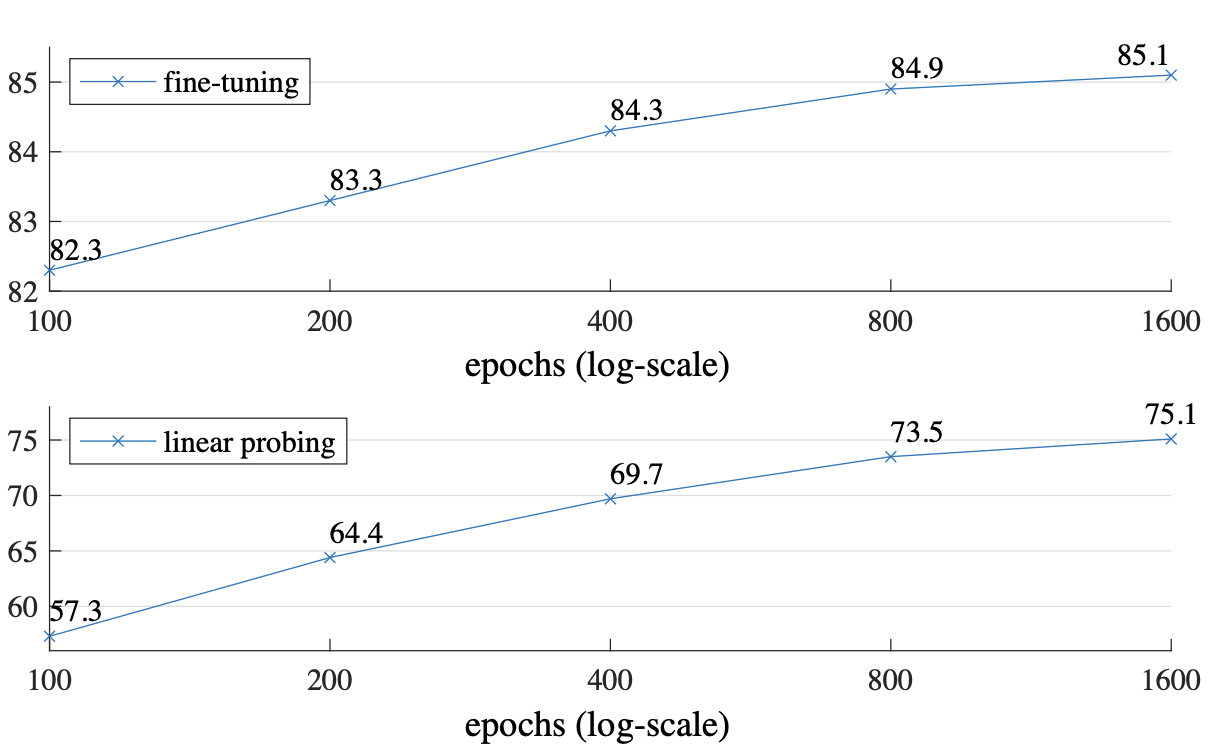

BEiT는 token을 맞추고 MAE(이 논문)는 pixel reconstruction을 하는데, 픽셀단위로 보는 게 더 좋았던건가.
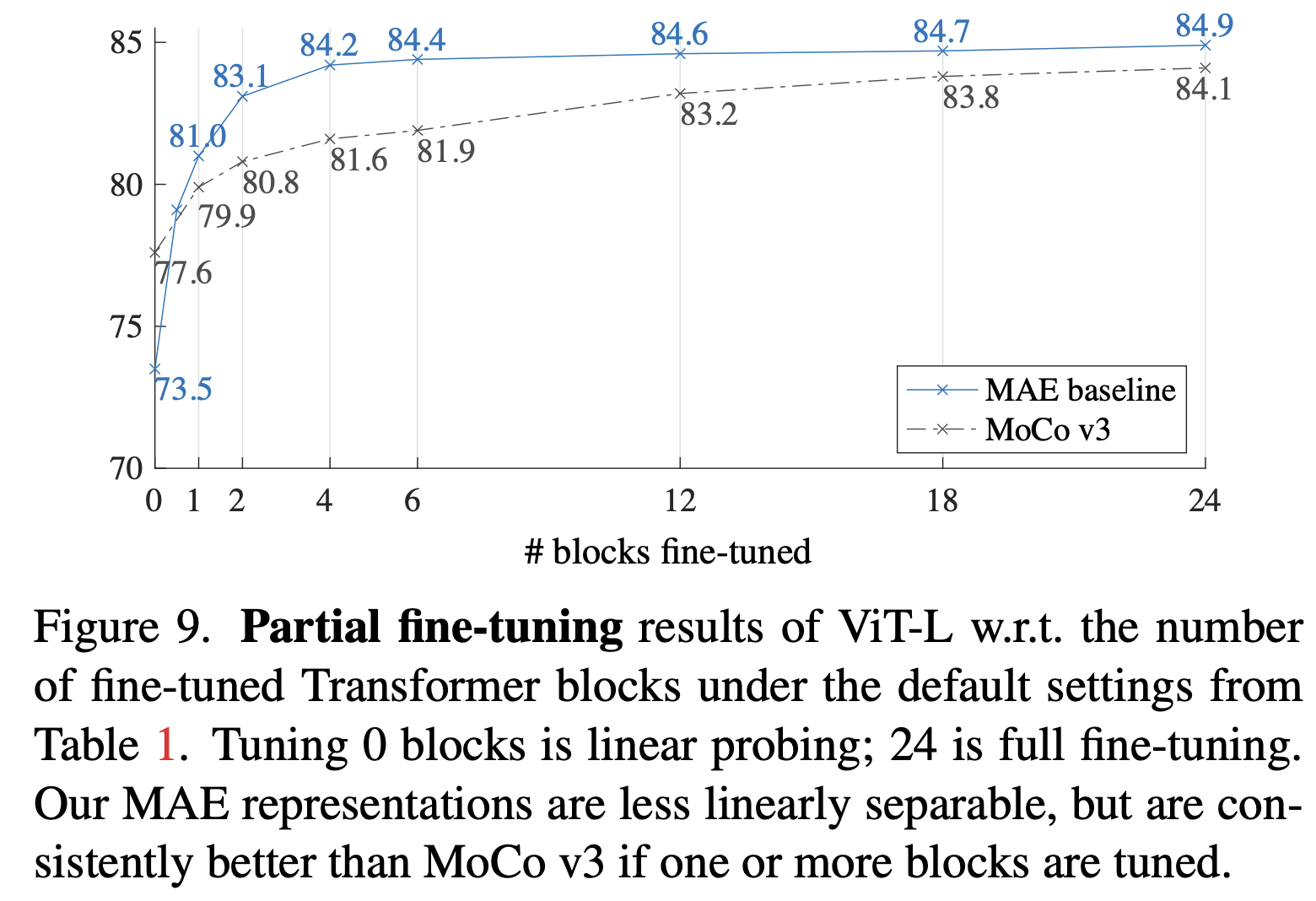
아까 그 Linear probing은 tuning0이고, 24는 전부 finetuning 한거다. finetuning은 다 하는게 성능이 좋구나.
Transfer Learning
Object Detection
Dataset: COCO
FPN구조로 ViT를 사용해야해서 upsample, downsample 적용.
fair comparison을 위해 hyperparam search 사용했다. learning rate, weight decay, drop path rate, and
fine-tuning epochs를 서치했다.
Image Segmentation
Dataset: ADE20K
UperNet 사용, lr만 서치해서 사용.

Visualization
IMIK학습하고 COCO validation set에서 빈칸추론

한줄 요약
information density라는 관점에서 NLP와 비전을 바라보고, 같은 autoencoder구조로 묶어 도메인을 바라보며 차이를 풀어냈다는 점이 재밌는 논문이다.
'AIML 분야 > Vision Transformer' 카테고리의 다른 글
| Transformer와 CNN과 융합, 최강의 backbone 서베이 해보기? (EfficientNet V2, CMT, ViT, DeiT, Swin 등) (1) | 2021.08.04 |
|---|---|
| (읽다가 잠깐 드랍) Transformer, 진짜 필요할까? (2) (1) | 2021.06.03 |
| Transformer, 진짜 필요한건가? (1) | 2021.05.28 |
| [연구노트] CNN 안쓰는 3D Transformer를 만들어봤음 (for video action recognition) (0) | 2021.02.14 |
| [작성중] Deformable DETR: Deformable Transformers for End-to-end Object Detection (0) | 2020.12.24 |



댓글