[2022 추가]
이 글 왜이렇게 어그로가 끌렸지요??
블로그 방문자 상위 게시글에 이거 보일때마다 몹시 길티......
이 글에서 언급한대로 초기 ViT 유행일때는 왜 좋은지 연산 자체에 관심을 두고 비판적인 시각이 많았는데, 이제 transformer에서도 다들 중점을 두고 있는 부분이 아예 달라져서 메타가 바뀜.
처음 ViT 나오면서 아키텍쳐 위주로만 관심을 주던 2020 후반 ~ 2021 상반기 기준 개인적인 생각이며, 현재는 상당히 out-dated된 내용이라는걸 밝힙니다.
[2021.08.18] 덧붙이는 말
최근에 백본 조사하면서 보니까 CMT 좋네요......
아무래도 전에 쓴 글이 신경쓰여 이 말 쓰러 옴
모두 트랜스포머 합시다 ㄱ-
근데 또 EfficientNet V2가 많이 좋음
트랜스포머가 유행하면서 의아했던게, 진짜 self-attention이라는게 그렇게 중요한건가?
명시적으로 그런 레이어를 만들어 주는 것이 성능향상에 큰 기여를 하는건가?
왜 잘되는건가? CNN이 아니어도 되는건가? 그럼 그냥 MLP는?
이건 나만 드는 의문이 아닐거다.
게다가 최근 learning scheduler라든가 이것저것 많이 발전했기 때문에, 완전 동일 조건에서 실험하지 않았다고 하면 성능이 올랐다고 말하기도 어렵다. 또한 모델별로 hyperparameter tuning도 각각 해준게 아니라 본인 연구에 잘 되는 셋팅으로 고정하고 성능을 레포트할수도 있는거라 정말로 특정 아키텍쳐가 우수하다고 말하기는 어려울 수 있는 생각도 들었다. 파라미터 개수도 다를거고.
최근 arxiv sanity에 상위랭크된 논문을 보면, CNN과 transformer를 모두 사용하지 않고 오직 'MLP'만 사용함으로써 이런 transformer의 대유행에 대해 재고해보자는 논문이 나오고 있다.
아래 두 논문이 그 예시로 보인다.
- https://arxiv.org/pdf/2105.01601v1.pdf Pay Attention to MLPs
- 이 논문에서는 MLP Mixer를 인용하고 있다.
- https://arxiv.org/pdf/2105.08050v1.pdf MLP Mixer
두 논문 모두 구글 브레인에서 나왔으며, 저자가 겹치지는 않는 것으로 보인다. 각각이 독자적인 연구인가보다.
그래서 한번 이 주제에 대해서도 살펴보려고 한다.
1. Pay Attention to MLPs
우선, abstract에서 얘기하는 것은 다음과 같다.
- 이 연구는 attention이 없는 네트워크인 'gMLP'를 제안했다.
- MLP + gating으로 구성.
- 그런데 그 네트워크가 language나 vision applications에서 transformer와 유사한 성능을 보였다.
- 특히, Vision Transformer가 성능이 잘 나왔던 것은 self-attention 탓이 아니라고 말한다. 왜냐면 gMLP가 유사한 성능을 냈기 때문.
일단, transformer가 등장한 배경부터 생각해보자. NLP쪽에서 원래 RNN, LSTM과 같은 recurrent한 구조를 썼는데, recurrent하지 않은 모델을 만든게 트랜스포머다. NLP 안해서 모르지만, 이건 모델의 representation 자체가 한번에 모든 토큰을 보기 때문에 더 긴문장에서도 RNN보다 잘 translation 했던 것 같다. 어쨌거나 트랜스포머의 contribution이라하면, 1. recurrent하지 않고 한방에 전체를 봄. 2. multi-head attention을 통해서 token들간의 spatial information들을 잘 합쳐준다. (aggregation)
한편으로는, transformer에 대해 언급할때 inductive bias에 대한 말이 자주 나온다. 예를 들면 CNN같은 경우에는 모델 자체에서 이미 local 정보를 중요하게 보도록 뭔가 선입견? 아이디어? 가정? 같은게 이미 반영된 형태라고 생각할 수 있다. 이런 inductive bias는 장단점이 있을 것이다. 우리가 풀려는 문제가 정말 그 가정에 부합한다면 더 잘 풀겠지만, 그렇지 않다면 (이미지인데 local 정보가 안 중요하다거나 뭐 그런) 안좋을 것이다. transformer는 이런 관점에서 본다면 RNN, CNN보다 inductive bias가 더 적다고 볼 수 있다. 그렇기에 더 많은 데이터를 봐야 규칙을 찾아 학습을 할 수 있는 것이다. 더 robust할수는 있겠으나, 많은 학습을 요구할 것이다. 아무튼 transformer의 구조 특성상, Input에 따라 다른 weight이 할당되기 때문에 dynamic parameterization이 가능하다고 말한다.
물론 그렇다고 해도, transformer에 inductive bias가 아예 없는 것은 아니다. 왜냐면 특정 input에 명시적으로 가중치를 주자는 선입견이 반영된 모델이기 때문이다.
음. 어쩐지 UCF-101 학습하려고 action recognition을 위한 트랜스포머를 만들었을때라든가, 지금 실험하고 있는거라든가 확실히 학습 속도가 느리긴 했다. lr이 크면 아예 학습이 안되었고. 기분탓이 아니었나보다. 아니면 코딩을 망한건가..
[참고] inductive bias에 대한 reddit에서의 논의
https://www.reddit.com/r/MachineLearning/comments/d0gnyp/d_what_is_the_inductive_bias_in_transformer/
어, 그런데 그냥 MLP (with static parameterization) 자체가 임의의 function을 표현할 수 있다*고 하지 않나?
그러면 드는 의문이 있다. transformer에 존재하는 self-attention이라는 inductive bias가 성능을 위해서 반드시 필요한 것일까?
* 참고: Kurt Hornik, Maxwell Stinchcombe, and Halbert White. Multilayer feedforward networks are universal approximators. Neural networks, 2(5):359–366, 1989.
그래서 이 논문에서는 attention이 없는 MLP를 가지고 (gMLP) image classification과 MLM(masked language modeling) 문제를 풀어본다.
먼저 ImageNet에 적용한 결과, DeiT와 유사한 성능을 얻었다고 말한다. 이건 ViT와 학습환경이 거의 비슷하지만 regularization을 통해 성능을 개선시킨 모델이라고 한다. 게다가 MLP-Mixer(이것도 CNN, transformer 안 쓴것)보다 66%나 파라미터가 적은데 성능은 3%가 더 좋았다고 한다. ViT의 self-attention이 정말로 중요한건지 생각해봐야한다고 저자는 말한다.
BERT 셋업에서 MLM에도 적용해봤다. 그 결과, gMLP가 transformer와 유사한 정도로 perplexity를 낮추는 데에 성공했다고 한다. 또한 저자가 실험을 통해 밝힌 바로는, perplexity가 model capacity와 큰 연관이 있을 뿐이지 실제로 attention이 존재 하는지 아닌지에는 별로 영향을 받지 않았다고 한다. 실제로, model capacity를 늘려보니까 pretraining & finetuning 모두 성능 증가폭이 transformer와 유사했다고 한다. attention이 없는데도 말이다. 아무튼 BERT에서와 동일한 배치 사이즈, training step 개수로 학습한 결과 원래 BERT논문에 나왔던 것과 유사한 성능을 얻었다고 한다. (86.4% accuracy on MNLI and 89.5% F1 on SQuAD v1.1.)
하지만 BERT의 pretraining말고 finetuning을 할때에는 상황이 조금 달랐다. cross-sentence alignment가 필요한 task들(MNLI같은)에서는 트랜스포머 구조가 성능이 더 좋았다. 하지만 이는 MLP 크기를 키움으로써 해결할 수 있었다.
이렇게 attention이라는게 효과가 있는 NLP의 특정 태스크가 있는 반면 vision에서는 크게 효과가 없어보였기 때문에, 저자는 attention 매커니즘이 각각의 domain에서 필요한지에 대해 생각해봐야한다고 말한다.

모델은 심플하다. L개의 똑같이 생긴 block을 쌓아올린다.
input X는 n*d 차원이라고 하자. n은 sequence length, d는 채널축이다. ViT를 생각한다면 16*16 패치에 sequence length 16이라하면 n=16, d=16*16*3 (rgb 픽셀값)이 될 것이다. input output format을 BERT나 ViT와 동일하게 만들었다고 한다. 그래야 동일한 비교를 하니까.
U, V는 channel dimension 상에서의 linear projection. BERT에서 FFN의 크기가 768*3072인데, 이와 같게 설정했다고 한다.
시그마는 GeLU와 같은 activation function.
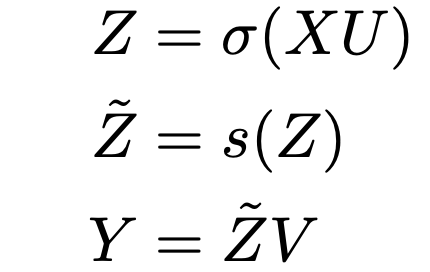
이 수식대로라면, 중간에 spatial 위치관계를 embedding하는 부분인 s(.)가 있고, 이 연산 전후로 channel단위의 linear projection이 있는 구조이다.
그러면 이 모델에서 중요한 것은 중간에 s함수인데, 이게 이름이 Spatial Gating Unit (SGU)이다. 이름에서 알 수 있듯이 spatial한 interaction을 잘 포착하도록 하는 유닛이다. inverted bottleneck 구조에서 영감을 받아서 SGU를 spatial depthwise convolution으로 구상하였다고 한다. transformer와 다르게 position embedding을 사용하지 않는데, 그 이유는 그런 정보를 s(.)에서 포착할 수 있기 때문이라고 한다.
Spatial Gating Unit (SGU)
위 수식에서 s() 부분에 대한 설명이다.
s(Z) = Z * f(Z)이다. *는 element-wise multiplication.
그리고 f(Z) = WZ+b인데, 간단한 linear projection이다. 여기서 W는 n*n matrix로, sequence length n과 관계가 있다. token간의 관계를 임베딩하겠다는 의미. 각 토큰은 (ViT에서처럼) spatial 위치단위로 쪼갰다는 것을 기억하자.
W, b는 각각 0,1로 정의하면 s(.)는 identity mapping으로 Initialization 되는 것이다. 이렇게 했다고 논문에서 밝히며, 실제로 identity로 이니셜라이즈 하는게 성능에 중요했다고 한다.
이부분을 고안하는데에 있어서 Gated Linear Units (GLUs)와 연관이 깊다고 한다. 다만 다른점이라고 하면, spatial dimension상에서 연산을 하기 때문에 cross-token 정보를 연산하는 것이 된다. channel상에서의 per-token 연산이 아니라고 한다.
참고로, 여기서 s(Z)를 연산할때 그냥 Z*f(Z)가 아니라 Z=(Z1, Z2)로 잘라서 하는 것이 더 효율적임을 나중에 알았다고 한다.
채널축을 따라 두 덩어리로 나눠서 연산을 하는것이다. 음, 그러면 output 채널수가 반으로 줄어드는거겠지?
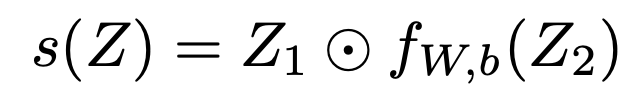
(여담)
transformer의 self-attention의 경우 3rd-order 관계까지 포착할수 있다. 그에 비해 SGU의 경우 2rd order까지 가능하다고 한다. 그런데 complexity는 둘다 input channel (d)와 linear하게 비례하며, sequence length (n)과는 quadratic한 관계를 가진다고 한다.
음...? 안좋은거 아니야?
Experiments - Vision Domain
vision domain용 모델 3가지 버전이 있나보다.
앞서 언급했던것같은데 ViT에다가 간단한 regularization을 통해 약간 개선시킨 버전이 DeiT라고 했다.
실제로 transformer가 overfitting이 심하기 때문에 적용했던건데, 실험을 통해 이 gMLP (논문의 모델) 또한 overfit이 심한 현상이 발견되어 여기에도 DeiT와 같은 방식으로 regularization을 적용했다. 아래 표에서 stochastic depth의 survival probability를 지정하는게 이 내용에 해당된다.

아래는 실험결과. DeiT급 성능으로 괜찮긴 한데 EfficientNet이 워낙 좋았어서 그런지 그걸 이기긴 어려웠나보다.
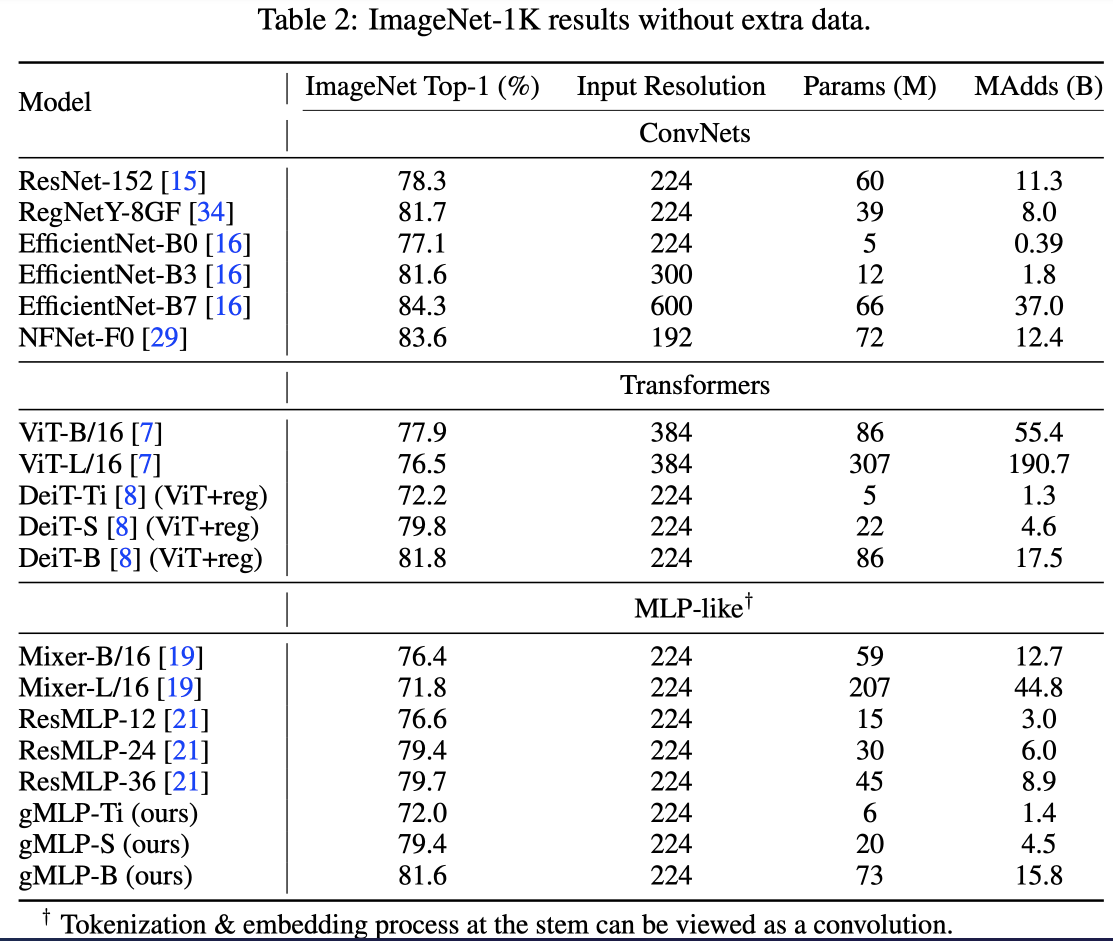
trade-off가 ViT계열보다 좋았다는걸 언급하는데 아래 그래프 보면 솔직히 잘 모르겠다. 거의 똑같은듯?
그리고 그림에는 없지만 EfficientNet이 당연히 훨씬 더 좋았다. 위 테이블에서 B0, B3을 보면 그렇다.
뭐, 이 논문의 contribution 자체가 vision쪽에서 MLP로 SOTA를 내는 게 아니라, transformer가 vision쪽에서 정말 메리트가 있냐는걸 따져보는것이기에 핵심은 self-attention이 아니어도 vision에선 상관이 없다... 정도일까.
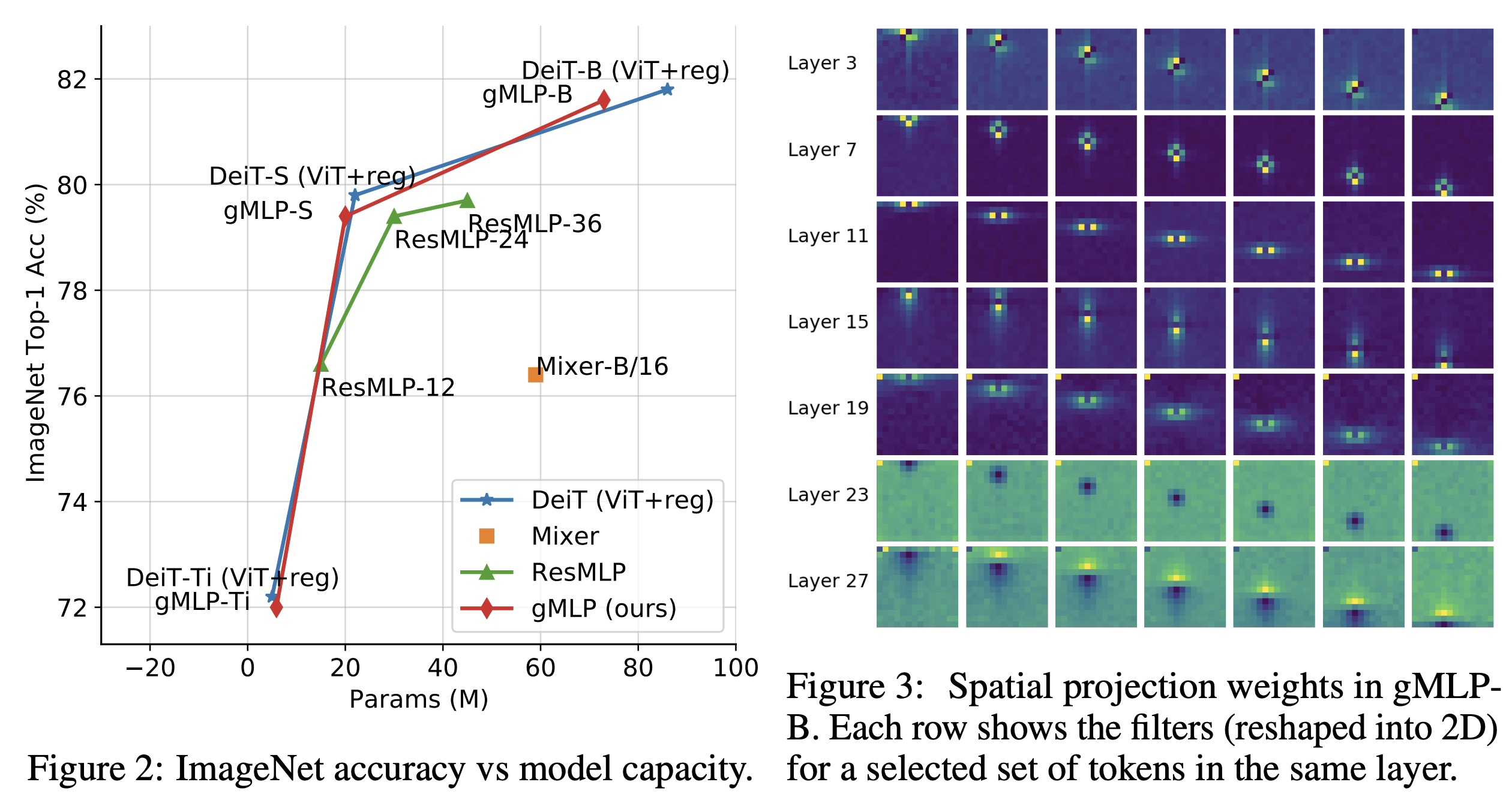
Figure3도 꽤나 재밌는데, spatial projection의 matrix를 2D로 reshape해서 보여준 것이다.
뭔가 locality와 함께 spatial invariance가 포착되는게, convolution과 비슷하지만 square shape이 아닌 커널을 배우는 느낌이다!
Experiment - NLP (MLM Tasks)
positional encoding 안쓴다. 또한 <pad> token도 의미 없어서 제외
Ablation1
원래 transformer BERT를 3가지 경우로 나눴다. 기존 BERT, relative position biases 추가한 것, bias 추가하긴 했는데 softmax에서 content-dependent term을 제외한 것 (= attention-free transformer로서, Synthesizer로 볼수 있다고 한다)
NLP에 그렇게 관심은 없어서... 아무튼 결과를 보면 self-attention이 되게 중요했다. 그렇지만 이 논문에서 제시한 모델을 가지고도 유사한 성능을 달성할 수 있었다.


Ablation2: Model Size
모델 사이즈를 늘리면 transformer 성능과의 갭이 줄어든다.
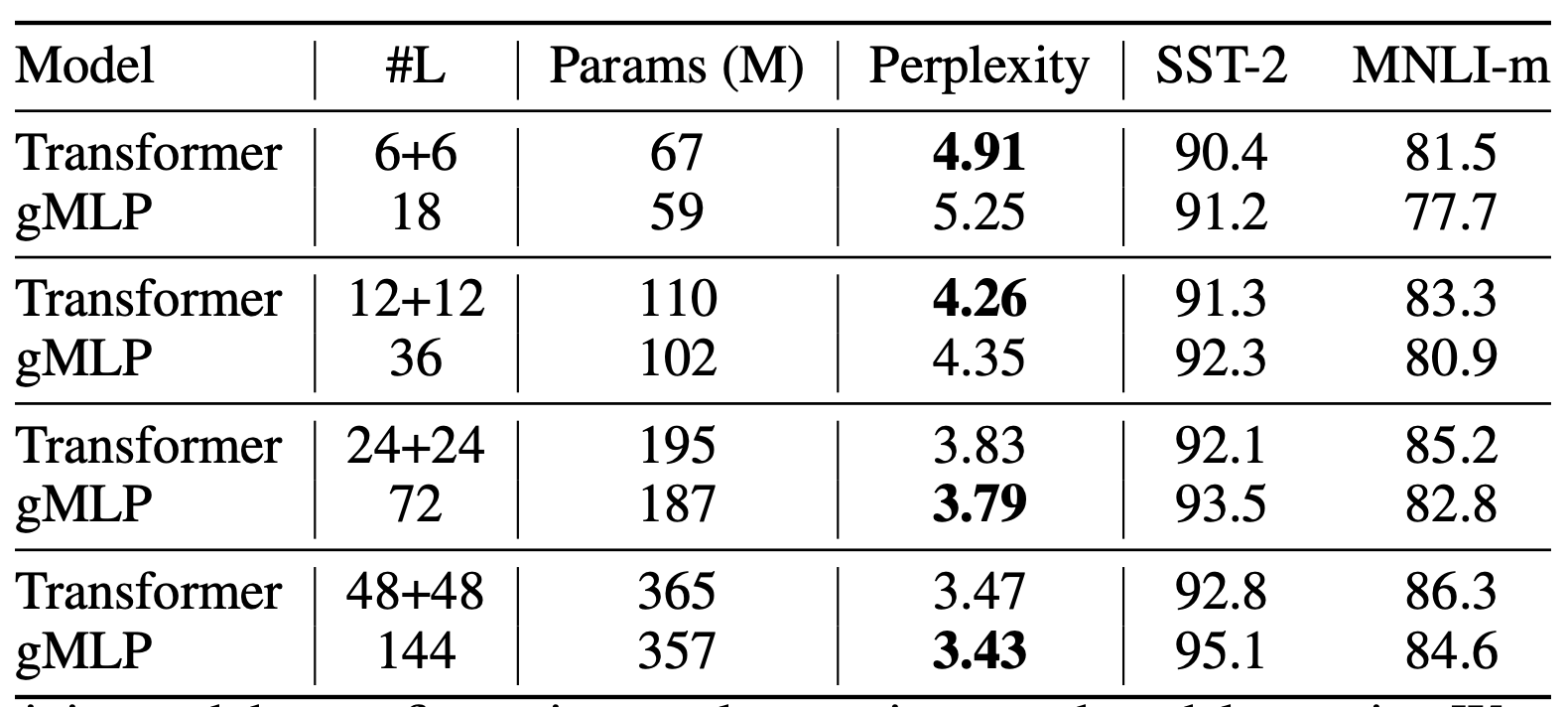
이 뒤에도 뭐 있긴 한데... 흥미를 잃었다. NLP 안해서...
vision 얘기는 그냥 앞에 저게 끝인가보다. Conclusion을 읽어봤는데 딱히 재밌는 말이 없어서 그냥 이만 글을 마무리하려고 한다...
결론은 NLP에선 transformer가 중요하고, vision에서는 딱히 아니라는것 같은데. Convolution과 비교하는 언급도 딱히 없고 그렇다.
NLP에서 attention하나를 gMLP에 추가하면 성능이 좋다든가, finetuning task에서는 MLP가 별로라거나, 모델 사이즈 키우면 transformer와 성능이 유사해진다든가 등의 얘기가 있었다. 약간 이런 실험 결과를 통한 1차원적인 언급만 하고있다.
그냥 내 의견 아무말.
vision쪽을 보고 생각하면 이렇다.
1. transformer든 MLP든간에 성능 차이가 거의 없으며 둘다 EfficientNet보다는 best performance 관점에서도 trade-off 관점에서도 모두 안좋으니까 역시 convolution이 짱이라는 생각밖에 안든다.
2. 게다가 Figure3을 보면 spatial projection weight에 대한 visualization이 있는데, locality가 굉장히 강하다. 저런 모양이라면 기존에 원래 쓰던 convolution의 커널들이 거의 커버할 수준이기 때문에, convolution 연산이 상당히 중요해보인다.
(결론)
- 이 논문에 따르면, transformer를 비전에 끌고오는건 좋은데 그걸로 convolution 연산을 대체할 메리트는 없다고 보여진다.
- object detection에서 DETR와 같은 논문처럼 vision task에서 기존에 곤란했던 부분에 응용을 하는건 괜찮은 것 같다. (자세히 안봐서 모르겠지만, 아무튼 end-to-end가 되었으니 좋을것같은데)
이런 부분을 논문에서 좀더 공격적으로 논의해줬다면 좋았을텐데 거의 뒷부분 NLP쪽 분석에 중점을 둔것같아서 아쉽다.
왜냐면 (NLP안해봤지만) NLP쪽에서는 거의 transformer 기반이 국룰이지 않았나? 요즘 transformer가 뜨면서 온갖 논문에서 transformer로 1절 2절 3절 뇌절을 하는건 비전쪽이고, 그래서 비전쪽에 적용하는 것에 대해 비판적인 시각을 가진 연구가 필요하다고 생각한다.
NLP에서 검증하는건 좋은데, 현 상황에서 중요성에 비해 비전쪽 얘기가 너무 없다. 물론 내가 더 보고싶은데 마음에 안차서 서운한건지도?



댓글