내맘대로 정리하는 개념.
출퇴근시간에 게임하는것도 슬슬 질린다.
자투리 시간에 심심하니까 이거나 좀 채워봐야지.
찾기 귀찮아서 그냥 아는거 정리하는것도 많아서 틀릴 수 있음.
빠르게 한번 훑고 세세한 개념 설명 추가해야지
각 주제 관련해서 참고해볼 자료를 링크로 걸어두었다.
Ian Goodfellow- Deep Learning 책 목차 보면서 떠오르는대로 정리해도 될듯
https://github.com/janishar/mit-deep-learning-book-pdf/tree/master/chapter-wise-pdf
GitHub - janishar/mit-deep-learning-book-pdf: MIT Deep Learning Book in PDF format (complete and parts) by Ian Goodfellow, Yoshu
MIT Deep Learning Book in PDF format (complete and parts) by Ian Goodfellow, Yoshua Bengio and Aaron Courville - GitHub - janishar/mit-deep-learning-book-pdf: MIT Deep Learning Book in PDF format (...
github.com
1. 머신러닝과 딥러닝.
http://www.tcpschool.com/deep2018/deep2018_deeplearning_intro 딥러닝
https://blog.naver.com/mhn_noonai/222285873816 머신러닝
https://tensorflow.blog/%ED%95%B8%EC%A6%88%EC%98%A8-%EB%A8%B8%EC%8B%A0%EB%9F%AC%EB%8B%9D-1%EC%9E%A5-2%EC%9E%A5/1-3-%EB%A8%B8%EC%8B%A0%EB%9F%AC%EB%8B%9D-%EC%8B%9C%EC%8A%A4%ED%85%9C%EC%9D%98-%EC%A2%85%EB%A5%98/ 머신러닝
딥러닝은 머신러닝 방법 중 하나로, neural network을 기반으로함.
MultiLayer Perceptron같은거 생각하면 되는데, 신경망 가중치(weight)를 입력에 곱하고 bias를 더하여 output을 내는 구조가 여러 레이어 쌓여있다고 보면 된다. loss function을 정의하고 forward 후에 backpropagation하여 각 learnable parameter들에 대해 loss를 편미분해서 gradient descent하면서 loss minimization하는 방향으로 learning rate만큼 학습하는 것.
다른 유명한 머신러닝 알고리즘들에 비해서 데이터를 많이 필요로 하다보니까, 최근들어 장비 가격이나 데이터에 대한 접근성이 완화되어서야 유행한 듯.
머신러닝은 데이터에 기반으로하여 규칙성, 패턴을 찾는 알고리즘 혹은 통계적 모델이다. neural network 말고 일반적인 머신러닝 알고리즘도 다양하다. 되게 다양한게 종류를 크게 2가지로 나눈다.
supervised, unsupervised learning. reward를 줘서 학습하는 reinforcement learning도 있는데 일단 이건 논외로 한다.
supervised learning에는 linear, logistic regression이나 Naive bayes, SVM, K-nearest-neighbor, Decision Tree, Random Forest (classification)같은 알고리즘이 있다.
unsupervised learning에는 K-means clustering 등이 있다. (내가 비전 위주의 딥러닝을 다뤘다보니 이쪽은 안써서, 조금 나중에 쓰겠다.)
2. activation function.
https://deepinsight.tistory.com/113 활성화함수
https://hongl.tistory.com/236 GELU
왜 나왔는가
딥러닝이 퍼셉트론 기반으로 하다보니까 신경망에서 착안하였고, 그래서 입력신호를 활성화할지 말지 activation하는 부분을 모방하여 나온 개념. 출력값의 범위가 정해지는 장점도 있음
종류
sigmoid, tanh / relu leakyRelu elu maxout 등등이 있는데, 최근에 논문 보면 nlp나 ViT 계열 등에서 gelu 많이 쓰는 것 같다.
생각해보기
- Sigmoid 대신 Relu를 사용하는 이유는?
- Relu의 단점과, 이를 대신하기 위한 방법은 무엇이 있나요?
2-2. non linearity?
https://mole-starseeker.tistory.com/m/40
비선형성이라는건 직선으로 표현되지 않는다는 의미다. 평범한 feedforward neural network를 생각하면 그냥 행렬 weight곱과 bias 더하는건데, 선형대수학 배울 때 linear combination과 span을 떠올리면 이 모델은 주어진 representation space가 한정되어있다는걸 상상할 수 있다. 더 복잡한 것들을 표현하기 위해서는 선형적이지 않은 변환이 가능해야하며 그래서 activation function을 쓰는거다.
(참고: bias를 통해 활성화함수가 적용되는 기준을 바꿀 수 있다)
주로 이거 설명할때 다들 XOR 연산을 언급한다.
2-3. bias? variance?
https://gaussian37.github.io/machine-learning-concept-bias_and_variance/
그 바이어스 말고 모델 바이어스요. 의식의 흐름을 따라 생각난김에 아래 추가한다.
3. weight initialization.
- https://velog.io/@cha-suyeon/DL-%EA%B0%80%EC%A4%91%EC%B9%98-%EC%B4%88%EA%B8%B0%ED%99%94Weight-Initialization- 종류별
- https://kjhov195.github.io/2020-01-07-weight_initialization/ torch default?
- xavier나 he 많이 쓴다.
- nn.Linear는 xavier, conv는 he를 default로 두는 것 같다.
- 둘다 이전 레이어의 뉴런 개수에 반비례하게 표준편차를 두는 방식이다.
- 뭐 아니면 transfer learning, pretraining 개념에서 미리 학습된거 불러오거나.
4. loss function
- https://ynebula.tistory.com/28 cost function
regression이면 MSE, MAE 등. (이외에도 regularization term에 비슷한 값 나오라고 L2, L1 norm 넣거나)
classification이면 주로 Cross Entropy Loss.
Cosine Similarity도 많이 쓴다. self-supervised learning할때 augmentation 다양하게 적용하고 feature들 간에 비슷하라고.
생각해볼 것
Supervised learning과 Unsupervised learning의 Objective fuction과 그 차이를 딥러닝 모델 중심으로 설명해 주세요
5. Gradient Descent? Stochastic?
- GD
- 로스를 줄이기 위해서 일정 lr만큼 단계적으로 gradient 방향으로 학습 파라미터를 업데이트 하는데, 모든 데이터에 대해서 한번에 계산하기엔 메모리가 너무 든다.
- 아무튼 배치(전체 데이터)로 학습하는게 일반 gd.
- SGD
- 배치가 1이면 sgd.
- 단어 자체의 의미: stochastic = probabilistic + time
배치에 들어갈 하나의 데이터가 랜덤하게 선택됨을 의미. 그런데 노이즈가 너무 심하다.
- Mini Batch SGD
- 그래서 대안으로 많이 쓰는 게 미니배치 sgd. 흔히 말하는 배치 사이즈 256 그런거다.
Gradient Descent(경사하강법) 와 SGD( Stochastic Gradient Descent) 확률적 경사하강법
안녕하세요 오늘은 Gradient Descent 와 SGD(Stochastic Gradient Descent)에 대해 알아보도록 하겠습니다. Gradient Descent (경사하강법)이란? 손실(cost) 를 줄이는 알고리즘 입니다. 간단히 말하자면, 미분..
everyday-deeplearning.tistory.com
딥러닝 overfitting을 막는 방법으로 고전적으로 많이 언급되는 것이 batch normalization, weight regularization, dropout 등이 있다.
이름이 정규화인게 3가지나 있어서 이거 공부할때 헷갈린다. Normalization, Standardization, Regularization. https://realblack0.github.io/2020/03/29/normalization-standardization-regularization.html
[딥러닝] 정규화? 표준화? Normalization? Standardization? Regularization?
딥러닝을 공부하다 보면 “정규화” 라는 용어를 참 자주 접하게 된다. 그런데 애석하게도 Normalization, Standardization, Regularization 이 세 용어가 모두 한국어로 정규화라고 번역된다. 이 세가지 용어
realblack0.github.io
6. Normalization
Normalization의 정의는 데이터 값의 스케일을 원하는 범위로 스케일링 하는 것. 학습에 데이터 범위가 안좋은 영향을 주는걸 막기 위함.
특히나 여기서 mean 0 std 1의 표준정규분포를 따르게 하는걸 Standardization이라하고, normalization 기법의 일종이다.
https://sonsnotation.blogspot.com/2020/11/8-normalization.html
[머신러닝/딥러닝] 8. Normalization
sonsnotation.blogspot.com
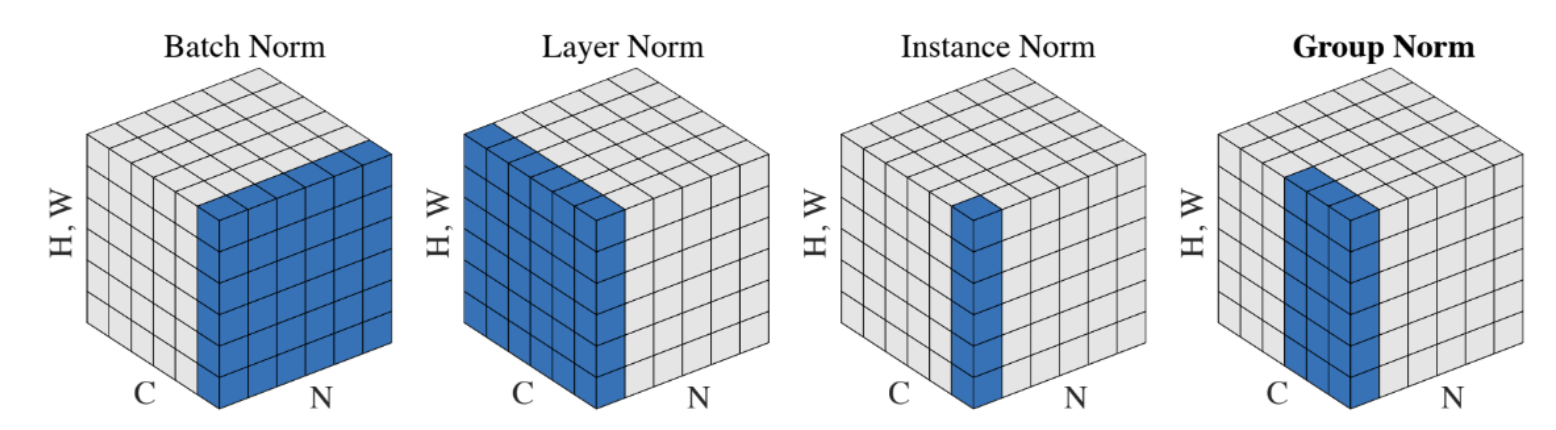
가장 흔한 Batch Norm, 그리고 다른 normalization
BN
- 개념
- batch norm은 internal covariance shift 때문에 쓴다. 다음 레이어로 갈때 분포가 바뀔 수 있기 때문.
- 0 mean 1 std 분포로 노멀라이즈한다. 하지만 input을 가지고 statistic을 구하는 것 뿐만 아니라 output에도 scaling, shift를 적용함. (수식 봐주자) 얘네는 backprop으로 학습된다.
- 쓰는 이유: 쓰는 이유는 활성화 함수의 비선형성을 잃게 될 수 있어서, 이를 보전하기 위함이라함.
- 물론 요즘에는 shift를 해결해서라기보다는 다르게 설명하는듯 하다만...
- train test모드 이야기
- data statistics 뽑아쓰는건 학습모드에서만 그렇다.
- 인퍼런스때에는 인풋 데이터의 mean std를 사용할수는 없는 노릇이니 deterministic하게 한다.
- 학습때 사용한 running mean, running variance를 불러와서 활용.
https://eehoeskrap.tistory.com/m/430 BN 설명 참고
[Deep Learning] Batch Normalization (배치 정규화)
사람은 역시 기본에 충실해야 하므로 ... 딥러닝의 기본중 기본인 배치 정규화(Batch Normalization)에 대해서 정리하고자 한다. 배치 정규화 (Batch Normalization) 란? 배치 정규화는 2015년 arXiv에 발표된 후
eehoeskrap.tistory.com
다른 normalization 기법
아무래도 배치 사이즈가 작을 수 밖에 없는 task도 있고, recurrent한 구조는 bn을 적용하기가 뭐하다.https://subinium.github.io/introduction-to-normalization/
Introduction to Deep Learning Normalization
수 많은 정규화들을 한번 가볍게 읽어봅시다.
subinium.github.io
- LN은 레이어에 하는데, 미니배치에서 feature dim이 같아야하는구나. 그래서 RNN같은거에 효과적이래.
- IN은 채널마다 따로해서, GAN style vector 얘기.
7. 모델 Generalization을 위하여? Overfitting 막기?
이것저것. 전반적으로 참고하려고 한다. 여기 블로그에도 AIML 기본기 관련글이 많다.
https://glanceyes.tistory.com/entry/Deep-Learning-%EC%B5%9C%EC%A0%81%ED%99%94Optimization
딥 러닝에서의 일반화(Generalization)와 최적화(Optimization)
2022년 2월 7일(월)부터 11일(금)까지 네이버 부스트캠프(boostcamp) AI Tech 강의를 들으면서 개인적으로 중요하다고 생각되거나 짚고 넘어가야 할 핵심 내용들만 간단하게 메모한 내용입니다. 틀리거
glanceyes.tistory.com
Regularization.
https://velog.io/@sp1rit/Regularization Normalization과 Regularization
https://huidea.tistory.com/154. L1, L2 설명
[기술면접] L1, L2 regularization, Ridge와 Lasso의 차이점 (201023)
더보기 Q. L1, L2 regularization 을 각각 설명하세요 Q. Ridge와 Lasso의 차이점 Q. L1, L2 regularization 을 각각 설명하세요 딥러닝 모델 과적합을 막는 방법에는 세가지가 있는데 - batch normalization..
huidea.tistory.com
https://rain-bow.tistory.com/entry/Semi-Supervised-Learning-SSL-%EC%86%8C%EA%B0%9C-%EB%B0%8F-%EB%8F%99%ED%96%A5 일반적인 L1, L2 외에 Regularizer라고 불리는 것들
Semi-Supervised Learning (SSL) 소개 및 동향
Regularization(정규화) input-output pair를 이용해 모델을 훈련시키는 supervised learning은 input으로 부터 output의 패턴을 정의하는 것입니다. 충분한 양의 데이터로 부터 유의미한 특징을 도출해내어 Erro..
rain-bow.tistory.com
06) 기울기 소실(Gradient Vanishing)과 폭주(Exploding)
깊은 인공 신경망을 학습하다보면 역전파 과정에서 입력층으로 갈 수록 기울기(Gradient)가 점차적으로 작아지는 현상이 발생할 수 있습니다. 입력층에 가까운 층들에서 가중 ...
wikidocs.net
L2 Regularization. Weight Decay.
https://sanghyu.tistory.com/88
[PyTorch] Weight Decay (L2 penalty)
Weight decay를 하는 이유 한마디로 말하자면 overfitting을 방지하기 위해 weight decay를 한다. overfitting은 train dataset에 과도하게 맞춰져서 generalization성능이 낮은 것을 의미한다. 그래서 처음 본 t..
sanghyu.tistory.com
dropout 등 키워드.
data augmentation.
8. optimization
요즘 optimizer 종류도 많음. 이 글 아랫부분 참고 (Adam, RMSProp, AdaGrad 등...)
- https://velog.io/@chang0517/Optimizer-%EC%A2%85%EB%A5%98-%EB%B0%8F-%EC%A0%95%EB%A6%AC
- https://wikidocs.net/36033
- https://velog.io/@reversesky/Optimizer%EC%9D%98-%EC%A2%85%EB%A5%98%EC%99%80-%EA%B0%84%EB%8B%A8%ED%95%9C-%EC%A0%95%EB%A6%AC.
+ scheduler도 봐주자.
Q. local minima가 있음에도 딥러닝이 잘되는 이유는?
https://variety82p.tistory.com/entry/Local-Minima-%EB%AC%B8%EC%A0%9C%EC%97%90%EB%8F%84-%EB%B6%88%EA%B5%AC%ED%95%98%EA%B3%A0-%EB%94%A5%EB%9F%AC%EB%8B%9D%EC%9D%B4-%EC%9E%98-%EB%90%98%EB%8A%94-%EC%9D%B4%EC%9C%A0%EB%8A%94
9. input 관련
생각해볼 것
분포가 불균형한 비정형 데이터를 분류 할 때 발생하는 문제는 무엇인가요? 해결법은?
-> weight balancing과 샘플링.
CE Loss 발생시킬때 가중치를 줘서 해결하거나 (귀찮아서 난 주로 샘플링+이걸로함..) focal loss를 사용한다.
아니면 학습용 데이터셋 구성할때 애초에 샘플링을 통해서 맞춰주든가.
https://techblog-history-younghunjo1.tistory.com/74
[ML] Class imbalance(클래스 불균형)이란?
이번 포스팅에서는 머신러닝 분류 문제에 있어서 '클래스 불균형' 에 대한 간단한 주제에 다룰 예정이다. 머신러닝 모델을 평가하는 하나의 지표로서 F1 score이란 것을 고려한다. F1 score은 Precision
techblog-history-younghunjo1.tistory.com
이 블로그에 MLDL 관련글이 많아서 천천히 읽어보면 좋을 것 같다.
[주관을 확고히 하기 위해 생각해볼 지점]
Domain Knowledge가 머신 러닝 모델에 미치는 영향에 대해 프로젝트 경험을 중심으로 설명해주세요
머신러닝 모델을 활용해서 문제를 해결하려고 할 때 가장 중요하게 생각하는 것은 어떤 것인가요?
최근 가장 인상적으로 읽은 논문은 무엇인가요?
'전공 기본기를 다져요 > 지식 테스트' 카테고리의 다른 글
| AIML 개념 빠르게 정리해보기 (2): 딥러닝 특정 모델 관련 (0) | 2022.07.26 |
|---|
댓글