* 주관과 선입견이 몹시 가득한 글
요즘 논문 쓰느라 바쁜데, action recognition과 semantic segmentation쪽 citation 정리 하느라 잠깐 서베이를 하고 있다.
내가 얘네를 마지막으로 열심히 한 게 1~2년 정도 되어서 딱 트랜스포머 유행 직전이었다.
트랜스포머를 도입하기는 하는데 그냥 vanilla ViT 나올 시기라 적용을 한다해도 그렇게 성능적으로 메리트가 보이지는 않았고, 깃발 먼저 꽂는 사람이 임자네.. 싶은 그런 연구들 나올 때였음.
그럼 현재는 어떤가 봤는데 이게 뭐임? 트랜스포머가 쓸어감.
물론 이게 transformer가 우수해서 그런건지, 요즘 논문 쓰시는 분들이 대부분 transformer를 썼으니 그중에 좋은 것도 트랜스포머라 그런건지는 몰라도 확실히 분위기가 많이 변했다.
Action Recognition.
Kinetics
https://paperswithcode.com/sota/action-classification-on-kinetics-400
Papers with Code - Kinetics-400 Benchmark (Action Classification)
The current state-of-the-art on Kinetics-400 is MTV-H (WTS 60M). See a full comparison of 126 papers with code.
paperswithcode.com
아키텍쳐 자체가 CNN보다 우수하냐 아니냐에 대해 갑론을박이었는데 (여기에 대해서는 나도 작년에 굉장히 회의적으로 글을 썼던 기억이), 이제는 약간 그런 주제를 떠나서 transformer 아키텍쳐 특성상 내재된 generalization 능력(?)을 활용하기 (MAE처럼) + Foundation model(CLIP, ALIGN, Florence, CoCa 등)이 나오면서 SOTA를 깨고 있는걸로 보인다.
그런데 foundation model은 다들 additional dataset을 사용했기 때문에, 이거 거르고 보면 slowfast나 x3d나 swin이나 그게 그거인듯 싶고 (성능 차이는 있지만 크지 않음), Masked AutoEncoder는 확실히 성능을 상당하게 올렸다고 봐야할 듯 싶다. 엄청 주관적으로 transformer에서 가장 큰 수확 중 하나가 MAE 아닌가 싶다. 좋아하는 논문이라..
1위를 차지한 MultiView Transformer 논문을 보면 이렇다.

semantic segmentation 부분은 별로 크게 변화가 없어보인다.
cityscapes 기준으로 보면 여전히 좋은 OCR. 예전에 조사하면서 블로그에 적었던거랑 큰 차이 없다.
ADE20k를 보면 최신 모델들이 휩쓸어놨는데, ViT-Adapter, SwinV2, Mask DINO, MAE 등등이 보인다.
Swin+UperNet처럼 기존 segmentation 알고리즘에 백본만 바뀌는 정도는 그냥 그러려니 하고 넘어가는데, 현재 1등인 Mask DINO의 경우는 DETR 스타일이라 한번 봐줘야겠다. 뒷단에 upsampling 하려고 이런저런 짓들을 하는 기존 semantic segmentation 모델과 달라보인다.
https://arxiv.org/pdf/2206.02777v1.pdf Mask DINO

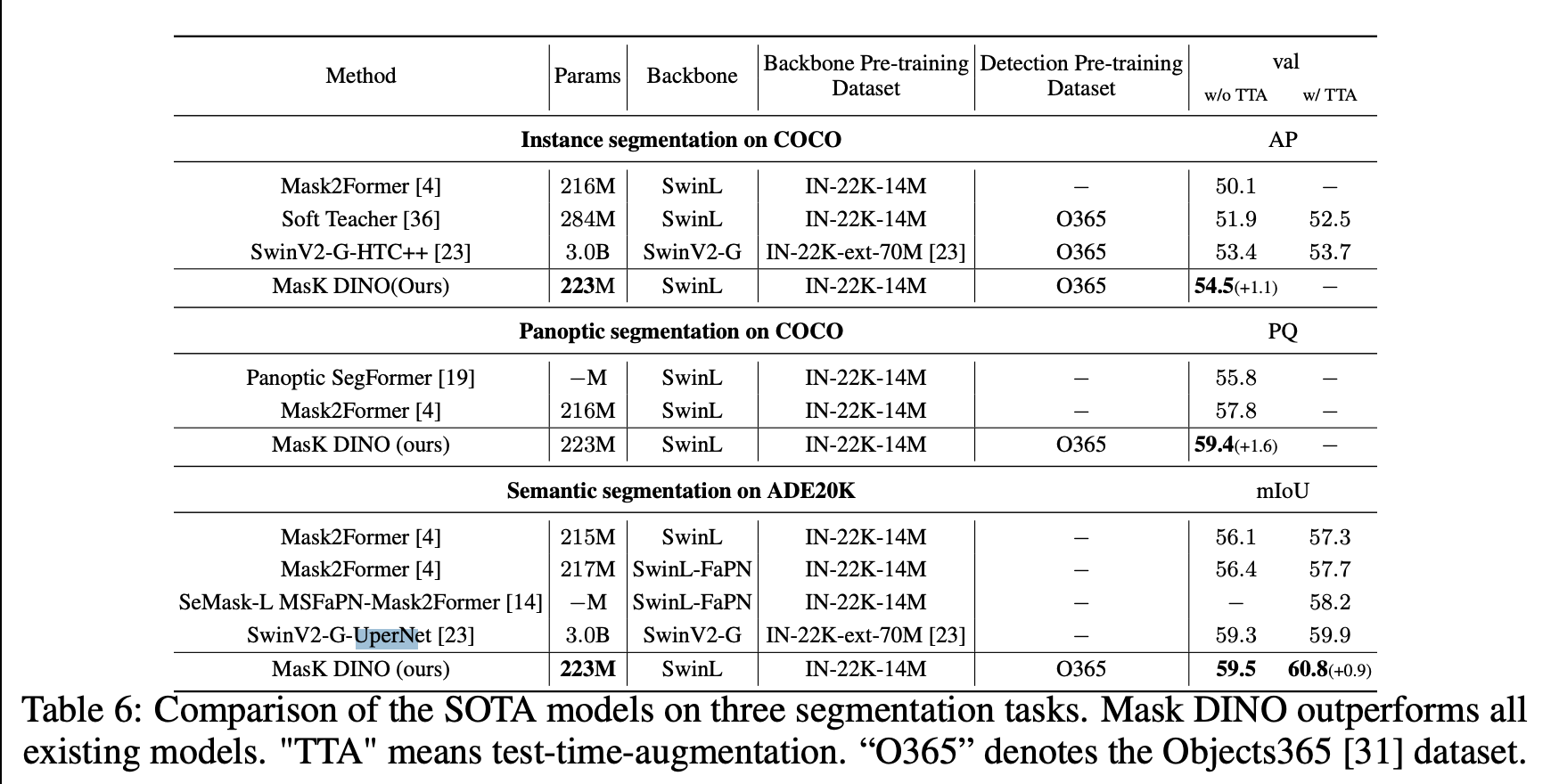
급한거 마무리하고 리뷰해야지.
'딥러닝 어쩌구 > Trendings' 카테고리의 다른 글
| [2021.11.25] survey (0) | 2021.11.25 |
|---|---|
| [2021.10.18] 서베이라는걸 해보자 (0) | 2021.10.18 |
| CVPR 2021 best paper candidates 목록 (0) | 2021.08.24 |
| [2021.03.09] arxiv sanity 구경 (0) | 2021.03.09 |
| [2021.02.13] arxiv sanity 대충 살펴보기 (0) | 2021.02.15 |

댓글