혹은 Contrastive Language-Image Pre-training.
뭐죠?
OpenAI에서 만들었다.
natural language supervision으로 부터 시각적인 개념들을 효율적으로 배울 수 있는 네트워크이다.
원논문은 무진장 길기 때문에... 그냥 웹사이트를 봐주도록 하자.
왜 했죠?
아직까지 딥러닝은 transfer learning이 잘 안된다. 특정 태스크를 잘하기 위해 어노테이션이 많이 필요한데, 다른 분야로 확장하려고 하면 또 성능이 안좋다. 논문에서는 어떻게 했냐면, generalization and transfer를 잘 하기 위해서 natural language를 flexible prediction space로 봤다! 이런 문제를 해결하기 위해서, 웹에 있는 이미지와 자연어 supervision을 통해서 모델을 학습한다. target task 하나에만 최적화하는 방식이 아니라 GPT-2, 3에서와 같이 zero-shot의 형태로도 학습이 가능하다. 그러니까 핵심은 benchmark에 직접 최적화하지 않음을 통해 generalization이 잘 되게 만든다는거다.
아래와 같이, 같은 바나나이지만 데이터셋의 특성에 따라 그냥 resnet은 generalization이 잘 안되기도 한다. 이 논문에서 제안한 CLIP은 꽤 강건한 성능을 보이고 있다.

왜 이렇게 했을까? 기존에 NLP에서는 BERT의 경우 raw text에서 바로 학습 했다. task-agnostic objective를 갖는 방식이다. 그 결과, 어노테이션이 비싼 NLP의 어노테이션을 활용하지 않아도 성능이 굉장히 잘 나왔다. 심지어 특정 task 전용으로 비싸게 label 매겨가며 학습한 것 보다도 더!
그런데 비전에서는 여전히 labeled dataset (ImageNet)에서 학습을 하는 게 표준화 되어있어서, 이 논문에서는 web text들로 사전학습을 한다.
ImageNet의 경우 zero-shot은 잘 안먹힌다고 하는데, 인스타의 ImageNet 관련 해쉬태그를 예측하도록 만들면 효과적이었다고 한다.
CLIP: Connecting Text and Images
We’re introducing a neural network called CLIP which efficiently learns visual concepts from natural language supervision.
openai.com
Approach.
단순한 pre-training task를 가지고도 각종 image classification 데이터셋들에서 zero-shot이 어느정도 잘 된다고 한다.
인터넷상의 text-image pair를 사용했다.
CLIP의 proxy training task: image가 주어졌다. 32768개의 randomly sampled text snippets중에서 뭐에 속하는지 연결하기.
저걸 맞추려면 모델이 다양한 visual concepts를 배우면서도 이름과 연관시킬 수 있어야한다.
이걸 학습하고 나면 이제 거의 임의의 visual classification task에서 잘 사용할 수 있다. 왜냐면 어떤 데이터셋이 dog vs cat을 맞추는거라고 하면, CLIP 모델은 'a photo of a dog'인지 아니면 'a photo of a cat'인지 text description을 맞추기 때문이다.
그니까 이름을 달아줬기 때문에 zero-shot에서 효과적으로 작동할 수 있다는게 핵심 아이디어로 보인다.
아래 그림을 보자.
1. 짝 지어주는거 학습함. N개의 image-text pair를 전부 맞춘다.
2-3. zero-shot classifier 학습함. 1과 같은 방법처럼 text encoder를 사용하는데, 여기 들어가는 description은 'a photo of a {오브젝트 이름}'이 된다는 것.

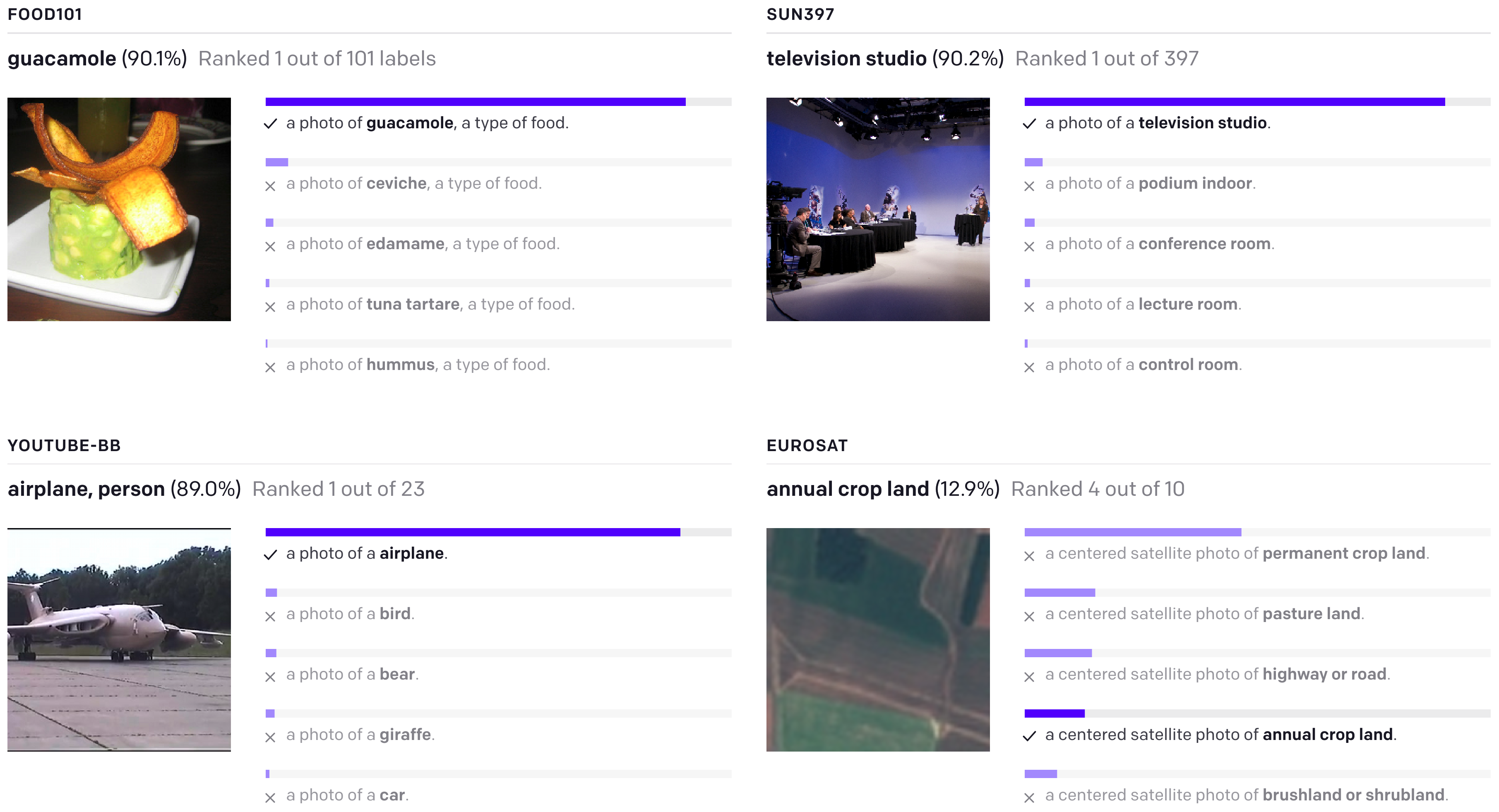
그러면 zero-shot CLIP classifier output은 이렇게 나온다. 체리피킹 아니다.
위에 그림대로 'a photo of a {클래스}' 이렇게 나온다.
contrastive learning, ViT 사용한 것이 알고리즘상의 특징. 이로 인해 학습 속도가 더 빨랐다고 한다.
아래 보니까 몇장의 이미지를 처리했는지를 가지고 성능 그래프를 찍었는데, 그러면 이게 효율적으로 지능을 배울 수 있는 방법이라는 의미 아닌가 싶다.



댓글