[2022 추가]
제가 카메라랑 depth estimation을 시작할지는 꿈에도 몰랐네요
과거에 이런 글을 쓰다니....
데이터 다운받고 관련 논문 읽는건 요즘 포스팅중.
그나저나 현대차 주가 언제 오를거임?
ㅡㅡㅡ
Visual Odometry 데이터셋을 사용하고싶다.
그런데 공홈에 별로 설명이 없다.
귀찮아서 사실 이것까지 보고싶진 않았는데, camera calibration도 공부해야하고 데이터셋에 들어있는 각 파라미터 의미가 뭔지 설명이 제대로 없어가지고 도통 알아먹을수가 없어서 읽어야겠다.
자율주행 궁금하기도 했으니 KITTI dataset 논문을 보자.
현대차 주주니까! 굿

"Are we ready for Autonomous Driving?
The KITTI Vision Benchmark Suite"
http://www.cvlibs.net/publications/Geiger2012CVPR.pdf
Abstract.
이 논문은 자율주행을 위한 데이터셋을 설명한다.
Task로는 stereo, optical flow, visual odometry/SLAM, 3D object detection 이렇게 있다.
본인들의 레코딩 플랫폼에 4개의 고화질 비디오 카메라, Velodyne 레이저 스캐너, SOTA의 localization system을 가지고 있다고 자랑한다.
389 stereo와 optical flow 이미지 페어들이 있고, 스테레오 VO 시퀀스는 39.2km 길이에 달하며, 200k가 넘는 3D object 어노테이션들이 있다고 한다. 참고로 한장의 이미지 안에는 15대의 자동차와 30명의 보행자가 최대라고 한다.
SOTA급의 알고리즘들이 기존의 Middlebury같은 데이터셋에서 좋은 성능을 달성하더라도 real world로 나오면 성능이 안좋아지니까, 이 데이터셋을 통해서 다들 연구 더 잘 해보자고 이 데이터셋을 냈나보다.
Introduction.
[참고] 이 논문이 나온게 11년인가 12년이라, 모든 설명은 이 시점 기준이다.
자율주행 시스템을 통해서 교통사고 발생시 사망률을 줄이는 등에 기여를 할 수 있는데, 이 시스템이 주로 GPS, laser range finder, radar, 환경에 대해 매우 정확한 지도 등에 굉장히 의존적이라고 한다.
요즘에 vision 쪽으로도 시도를 하면서 다양한 데이터셋이 나오는 추세였다고 한다.
이 벤치마크는 시골과 고속도로 사이에 있는 중간규모의 도시에서 취득했다고 한다.
카메라, 레이저 스캐너, 로컬라이제이션 시스템 각각은 캘리브레이션도 되고 동기화도 되어있다고 한다.
Stereo Matching와 Optical Flow Estimation 벤치마크
194개의 학습, 195개의 테스트 이미지 페어가 있다.
그 이미지들은 semi-dense (50%) ground truth로 rectification되어 1240*376 resolution이라고 한다.
이 데이터셋이 최초로 synthetic이 아니라고 한다.
3D VO / SLAM 데이터셋
22개의 스테레오 시퀀스, 총합 39.2km 길이.
예전에는 monocular에 짧고 저화질의 데이터 뿐인데다가 평가지표 구렸다는 얘기는 패스하겠음
3D object 벤치마크
cars, vans, trucks, pedestrians, cyclists and trams 같은 오브젝트에 대해서 3D bbox를 제공하고 있음.
Velodyne system에 의해서 3D point clouds를 만든다음에 이미지로 projection하는 식으로 레이블링 했기 때문에 정확하다고 함. 이게 뭔 뜻인가 했는데, LiDAR를 사용한 것 같다. 레이저 사용해서 반사하여 돌아오는 시간 측정해서 하는 것.
Calibration?
카메라간의 캘리브레이션. 체커보드 사용해서 corner를 detect하고, energy minimization 문제를 풀어서 파라미터들을 찾는다.
여담이지만 캘리브레이션 파라미터를 직접 구해야한다면 아래 링크를 따라해보자.
https://docs.opencv.org/master/dc/dbb/tutorial_py_calibration.html
Ground Truth
VO/SLAM의 GT는 GPS/IMU localization unit을 projection 시켜서 얻었다고 한다.
rectification 적용 후의 왼쪽 카메라 좌표계 기준이다.
Benchmark Selection

trajectory end-point 기반의 에러 집계 방식은 좀 그렇다. 왜냐면 시간이 지날수록 누적되기 때문.
그래서 Kummerle가 제안하기를, 고정된 거리에서 relative relations의 평균을 계산하자고 제안했다. 그래서 이 논문에선 이걸 두가지 방식으로 확장한다.
rotation, translation error를 합칠게 아니라 구분을 시켰다.
그리고 에러를 trajectory 길이와 속도를 가지고 평가한다.
그러면,

inverse compotional operator는 http://www2.informatik.uni-freiburg.de/~stachnis/pdf/kuemmerle09auro.pdf 를 찾아보자.
그럼 이런식으로 거리에 따라 나온다.
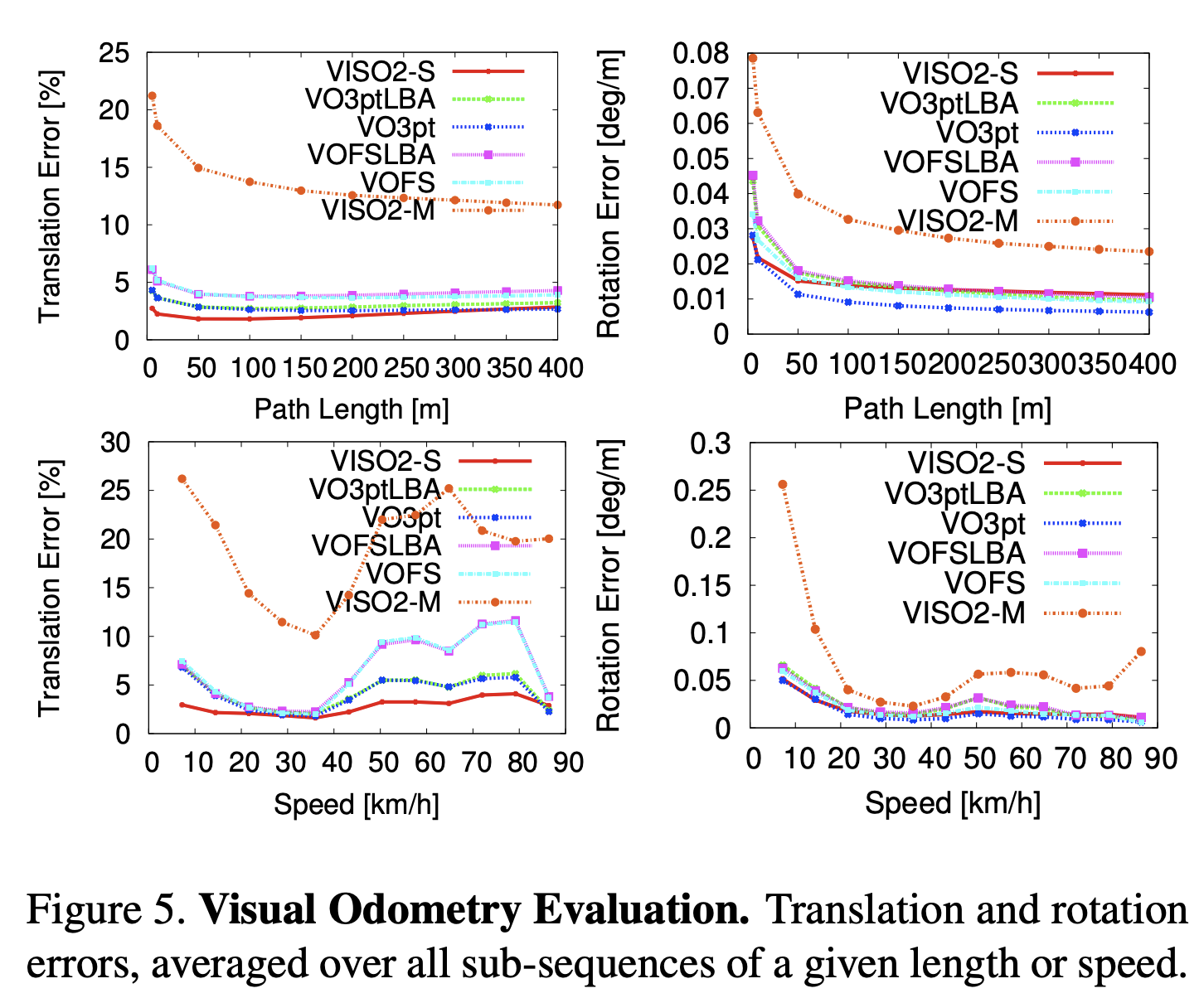
뭐.. 암튼 이 논문을 읽고 알게된건 역시 GPS같은걸 사용해서 global 좌표 GT를 구했다는 점이라든가, 스테레오 비디오라는점 (한쪽만 쓰면 모노큘러겠지 뭐), 취득할때 저렇구나... evaluation은 에러 누적문제땜에 거리별로 나누는구나... 기타 등등을 스르륵 알게 되었다.
음 재미없어
그래서 calib.txt 열면 들어있는 P0 P1 P2 P3은 뭐고, 각각에 들어있는 12개의 파라미터는 뭔데?
intrinsic calibration parameter인건가?
'AIML 분야 > Depth, Camera Pose, VO, SLAM 등' 카테고리의 다른 글
| 쓰는 중이다 [Camera Pose Estimation] 최근 논문 하나 살펴볼까 (0) | 2021.09.10 |
|---|---|
| [휘리릭 논문읽기] Learning High Fidelity Depths of Dressed Humans by Watching Social Media Dance Videos (0) | 2021.08.30 |
| DF-VO 논문 리뷰 & 코드 셋업해보기 (0) | 2021.06.17 |
| Video Odometry 연구 시작 - EndoSLAM 셋업해보자 (0) | 2021.05.04 |
| Video Odometry? SLAM? SfM? 아무튼 살펴본다. (0) | 2021.05.01 |



댓글