몰라서 기록하는 글.
Panoptic Segmentation 논문 한편을 리뷰했는데 여기서는 PQ, mIoU, AP를 사용했었다.
Semantic Segmentation 논문을 방금 리뷰했는데, 여기서는 mIoU와 pixel Accuracy를 사용했다.
한번 찾아보자.
아래 글에 잘 정리가 되어있고, 나는 그저 요약만 적을 뿐이다.
medium.com/@danielmechea/panoptic-segmentation-the-panoptic-quality-metric-d69a6c3ace30
kharshit.github.io/blog/2019/10/18/introduction-to-panoptic-segmentation-tutorial
www.groundai.com/project/panoptic-segmentation/1
towardsdatascience.com/metrics-to-evaluate-your-semantic-segmentation-model-6bcb99639aa2
1. IoU
이 식 하나로 설명 끝이다. 1이 가장 좋을거고, 0에 가까울수록 성능이 구릴 것이다.

아마 mAP와 마찬가지로 detection쪽에서 많이 봤을것인데, segmentation에서는 영역과 같을 것이다.
class별로 영역이 표시되어있을테니 (해당 class이다 / 아니다로 구분), 각각 IoU를 구해서 클래스별 평균을 내면 흔히 말하는 mIoU가 될 것이다.


2. AP (Average Precision)
precision, recall을 누적하여 커브를 그리고 그 안의 영역.
가장 certain한 결과부터 uncertain한 결과 순서로 나열하여 누적할 것이다.
AP도 마찬가지로 하나의 class에 대해 얼마나 잘, 정확히 감지했는지에 대해 구했으니 모든 클래스에 대해 평균을 내야할 것이다.
그것이 mAP.
3. Panoptic Quality (PQ)
panoptic segmentation에서 쓴다.
첫 식을 다시 쪼개면 두번째 식이 된다.
첫 파트 (SQ) : 예측한 segment가 얼마나 GT와 잘 매치되는가.
하지만 이는 TP에 대해서만 고려하고 있음을 알 수 있다. bad prediction에 대한 것이 없음!
precision, recall 등을 같이 잘 고려하여 모델 성능에 대해 더 잘 평가하기 위해서 두번째 텀 (RQ) 이 있는 것이다.

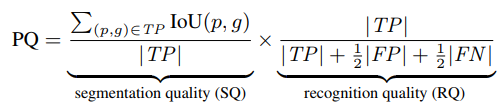
왜 쪼갰는가?
팬옵틱의 경우, 아래와 같이 같은 클래스에 여러 오브젝트가 존재하기 때문.
굉장히 애매하다.
세그먼트를 어떻게 매치해야하나? 인스턴스 끼리 다 구분지을 수도 없고, 그렇다고 클래스끼리 구분지어서 평가할수도 없고.

match prediction을 구한다.
IoU가 0.5 이상인 것에 할당하면 되는 것이다. 왜냐면 팬옵틱에서는 하나의 픽셀은 무조건 딱 하나의 GT에만 맵핑되기 때문이다.
여담이지만 panoptic-deeplab 논문에서도 관련 이슈가 언급되었던 기억이 난다. panoptic의 bottom-up 방식들이 instance annotation이 아닌 panoptic annotation을 사용하는 점. instance annotation이었다면 사람에 해당하는 영역, 넥타이에 해당하는 영역이 겹칠 수 있었다. 어쨌거나 panoptic 결과는 항상 1:1 매핑이라는 것.
그렇기 때문에 GT의 segment와 IoU가 0.5가 넘을 수 있는 것은 딱 하나의 segment 뿐이다.
아래 그림을 보자.
GT는 하나의 고양이모양 영역.
prediction이 4개의 고양이 인스턴스로 나왔고, 그중에 정말 GT랑 겹치는 영역은 2개의 고양이 인스턴스 영역이다.
GT의 모든 영역을 predicted와 매칭을 시도하여 평가할 것이다.
이때, GT 고양이 영역과 매칭될 segment를 찾는다면? IoU가 0.6인 녹색 영역과 매치하며, 위에 남는 부분은 매칭하지 않는다. 따라서, 주황색 부분이 False positive가 된다.

대략 이렇게 FP, FN을 고려한다.

더 자세한 예시는 맨위의 세번째 링크를 보면 될 것 같다.
SQ는 같은데 위에 글에서는 RQ라고 써있는게 저 글에서는 DQ라 써있다.
4. Pixel Accuracy
네번째 글을 보면 알 수 있는데, 별로 좋은 metric은 아니다.
precision, recall을 고려하지 않으면 단순히 가장 흔한 class로 예측해서 accuracy를 높일 수 있기 때문.
5. Dice Coefficient
IoU랑 항상 같진 않다.
아래 이미지와 같은 개념이다. 위의 IoU와는 다른 것을 알 수 있다.
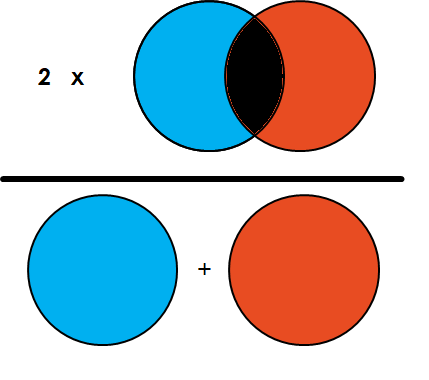
'AIML 분야 > Segmentation' 카테고리의 다른 글
| [Semantic Segmentation ] HRNet V2 실험 및 코드 (0) | 2021.02.18 |
|---|---|
| [Semantic Segmentation 조사 2] Deep High-Resolution Representation Learning for Visual Recognition (HRNet V2) (0) | 2021.02.17 |
| [Semantic Segmentation 조사 1] FastFCN 리뷰 (0) | 2021.02.16 |
| [2021.02.16. 연구노트] 깨알같은 디버깅 - panoptic deeplab (0) | 2021.02.16 |
| [연구노트] Semantic Segmentation 살펴보기 (0) | 2021.02.15 |




댓글