"A Survey of Deep Active Learning"
와! 서베이 논문이 나왔다!
2020년 9월이니까 완전 최근이다.
active learning 그냥 필요하니까 했던게 끝이라 method별로 카테고라이징이 잘 안 되었는데, 서베이 논문 한번 가볍게 살펴보면서 잡아줘야겠다.
물론 분량은 가볍지 않다. 30페이지.
읽어보니까 뇌 빼고 읽기보다는 정독해야겠다.
active learning을 처음 하는 경우에는 이 논문으로 쭈욱 정리하고 시작하면 좋을 것 같다.
아래 그림에서 딥러닝 모델, pool based approach, 일반적인 프레임워크에 대해 설명하고 있다.
그림을 보니 pool-based가 아닌 게 있던가 의문이 든다.
논문에 의하면 AL 기법은 membership query synthesis [8, 82], stream-based selective sampling [29, 85] and pool-based [95] AL from application scenarios [139] 이렇게 나뉜다고 한다.
그중에서 pool based가 가장 흔해서 이를 도식화한 것 같다.
Membership Query Synthesis
learner가 input space상에서 학습에 필요한 것을 선택할 수 있다. 심지어 learner가 만들어낸 데이터일지라도.
음. 안 와닿는다.
stream-based selective sampling
각 selection이 independent 하다. stream 내부에 있는 데이터 중에서 label 되어야 할 것을 선택.
이게 모바일이라든가, 뭔가 타임라인이 존재하는 경우에는 더 적절하다고 한다.
Pool-based Sampling
스트림과 다르게, 전체 데이터셋에서 rank를 매겨서 best query를 뽑는다.
많은 논문에서 이게 일반적인 경우이다.

AL의 query strategy에도 다양한 접근 방식이 존재한다.
uncertainty-based, diversity-based, expected model change 기반 등이 있다. 일단 이 문단은 생략하고 다음 섹터로 넘어가겠다.
2. THE NECESSITY AND CHALLENGE OF COMBINING DL AND AL
분명 AL query strategy는 많단말임? 근데 딥러닝 모델에 적용할때 난감한 부분이 있다.
뭐가 문제일까.
1. "Insufficient data for label samples"
(대략 이해한 바로는) AL에서는 보통 uncertainty같은걸 데이터 하나하나 평가하여 매기고 선택하는 편이다. 그런데 딥러닝의 성격에 이는 맞지 않는다.
2. "Model uncertainty"
딥러닝이 아무리 softmax 형태로 확률을 뱉는다고 해도, 너무 confident하다.
막상 까보면 성능이 그렇게까지 좋지도 않은 주제에 너무 자신만만하다.
AL strategy 중에서 uncertainty를 기반으로 하는 것이 되게 많은데, 딥러닝의 이런 특성이 문제가 될 수 있다는 것 같다.
3. "Processing pipeline inconsistency."
AL 기법들은 거의 (딥러닝 모델, classifier를 위한) feature representation을 기반으로 한다.
AL framework에서 DL 모델을 finetuning만 한다거나, classifier와 feature learning을 각기 다른 문제로 접근한다는 것이 문제라고 말한다.
이러한 문제들을 해결하기 위해서 고안된 방법이 몇가지가 있다고 한다.
- generative network 사용. 이 모델이 augmentation을 수행한다.
- high confidence sample의 경우, pseudo label을 부여하여 labeled training set에 사용.
- labeled, unlabeled를 같이 사용하여 semi supervised learning의 접근방식
- batch 단위의 sampling 방법.
- bayesian deep learning.
딥러닝이 너무 confident하다는 문제에 이 방법으로 대응하였다. - task-independent 아키텍쳐 디자인.
AL을 DL에 넣는 방식을 고안한 learning loss같은 논문도 있다.
이는 pipeline inconsistency 문제에 대한 대안으로 볼 수 있다.
여기서 feature learning과 classifier의 학습을 구분해 놓은 개념이 잘 이해가 가지 않아서, 방법 2에 해당하는 논문을 슬쩍 보고 내용을 보강하려고 한다. arxiv.org/pdf/1701.03551.pdfarxiv.org/pdf/1701.03551.pdf
4의 batch단위의 query가 도입된 이유에 대해 설명하겠다.
기존의 heuristic 기반의 query 방법들이 딥러닝에 적용되면 효율적이지 못하다는 논문이 나왔다고 한다.
보통 샘플 하나하나 단위로 평가하여 순위를 매겨 뽑는데, 딥러닝은 배치 단위로 학습이 되는데다가 분포를 배우는 것이기 때문에 개별 데이터 뿐만 아니라 데이터의 조합이 가지는 정보가 중요하다. core-set 논문을 보도록 하자.
아래 그림을 보면 쉽게 이해할 수 있다. (a)보다는 확실히 (b)가 효율적일 것이다.

3. DEEP ACTIVE LEARNING
여기부터 본격적으로 deep active learning 기법들에 대해 소개한다.
3.1, 3.2, 3.3에서 각각 AL query strategy, training step, model generalization에 대해 다룬다고 한다.
3.1 Query Strategy Optimization in DAL
3.1.1 Batch Mode DAL (BMDAL)
가장 학습에 도움이 되는 배치를 뽑는다는 의미. 사실 지금까지 봤던 것들 거의 이런 것 같다.
가장 나이브한 예시로는 모든 데이터를 평가 -> top K를 가지고 배치 형성하여 추출.
이건 방금 위에서 봤던 그림의 (a)와 같은 상황이 발생할 수 있기 때문에 별로 좋은 방법은 아니다.
이보다 나은 방법으로는 BMDAL처럼 개별 데이터가 많은 정보를 가지고 있으면서도 / 각각이 비슷하지 않고 다양한 데이터를 뽑는 것이다.
이런식의 접근 방식이 DL+AL의 시작이라 볼 수 있다.
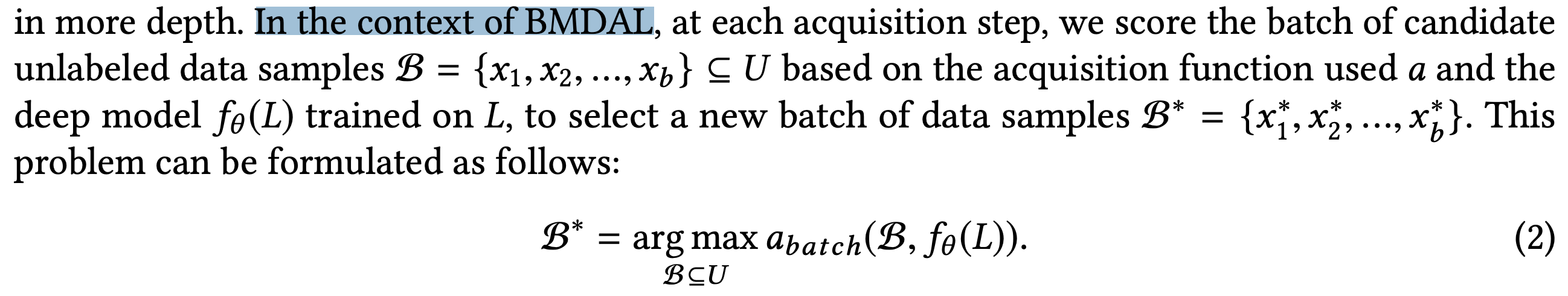
3.1.2 Uncertainty-based and hybrid query strategies
uncertainty가 많이 쓰이는 이유는 연산이 적으면서도 방법이 간단하기 때문이다. 고전적인 방법도 많다.
예시) Margin Sampling, Least Confidence, Entropy Sampling 등
이런 방법들을 그냥 적용할 수도 있지만, 역시 데이터 샘플단위로만 평가하면 데이터간의 상대적인 정보까지 고려할 수는 없다는 문제가 있다. 초기의 batch mode 기법들의 경우, sample들의 유사성에 지나치게 의존적이라고 한다. 이런 경우, 논문에서 'only good at exploitation'이라고 표현했는데, 다시말해 현재 모델의 decision boundary 근처에 있는 것에만 너무 집중한다는거다. 왜냐면 이게 가장 margin이며 entropy가 높기 때문. 하지만 이렇게 하면 실제 true distribution과는 이질적일 수 있다는 문제가 있다. 샘플들의 다양성이 떨어져서 그렇다고.
=> exploitation, exploration 모두 중요하다.
exploration은 딥러닝이 학습 초기에 여기저기 탐방하면서 다양성을 확보하는 그런 느낌으로다가 이해했다.
그렇다면 샘플들의 다양성을 확보하기 위해서는 어떻게 해야하는가. similarity score를 도입하여 서로 다른 샘플들을 뽑게 하는 방법은? 이걸 Exploration-P라는 논문에서 제안한다. "Deep Similarity-Based Batch Mode Active Learning with Exploration-Exploitation."
간단하게 설명하자면 이 논문은 feature space상에서의 샘플간의 similarity를 명시적으로 측정한다. 그리고 추가적으로, exploration도 보장하기 위해서 random sampling도 넣어주는 형태라고 한다.
이외에도 DBAL "Diverse mini-batch Active Learning." (2019, 아카이브, 아마존 리서치) 이라는 논문이 있다.
아래 알고리즘을 읽어보면, informative한 것들만 후보를 뽑고 그 다음에 K means로 골고루 정보를 뽑는다.

하이브리드 형태의 기법도 있다. 예를 들어 weighted incremental dictionary learning (WI-DL) 이 있다.
1. unsupervised feature learning stage
the key consideration is the representativeness of the data
2. supervised fine-tuning stage
the uncertainty of the data is considered
이런 두가지 관점을 잘 융합시킨 기법이 있다고 한다.
알고리즘에 수식 번호 써있는것 때문에 논문을 봐야 알겠지만, 대략적으로는 이해할 수 있을 것 같다.

이런 다양한 기법들이 있긴 하지만, 아직 완전한 것은 아니다.
이 논문에서 지적하는 고려사항은 데이터셋의 규모이다. diversity 기반의 접근 방식이 large batch size (query)에서는 좋겠지만, 배치 사이즈가 작다고 하면 uncertainty 기반의 기법이 잘된다고 한다. 이것은 데이터셋 규모에 따른 통계적인 특성 때문에 나타나는 현상이라고 한다. 하지만 우리가 다루는 것은 batch model active learning. 따라서 어떤 AL strategy가 잘 될지 판단하는 것은 어려운 일이다.
BADGE "Deep Batch Active Learning by Diverse, Uncertain Gradient Lower Bounds." (ICLR 2020)라는 논문이 있는데, 이게 uncertainty와 diversity를 동시에 고려할 수 있는 기법을 제안한다고 한다. 게다가 하이퍼파라미터로 조정할필요 없이 자동으로 uncertainty와 diversity이 밸런싱 된다고 한다.
Wasserstein Adversarial Active Learning (WAAL)에서도 이를 밸런싱하는 것에 대해 다뤘다고 하는데, BADGE가 이 논문을 고려한 것으로 보인다.
TA-VAAL (Task-Aware Variational Adversarial Active Learning)도 이런 하이브리드 형태의 기법을 사용함에 있어 밸런스를 어떻게 할지 고려했다고 한다. Variational Adversarial Active Learning (VAAL)에서도 data distribution과 uncertainty를 같이 고려한다.
이런 다양한 방법들이 있긴 하지만 softmax에서 uncertainty를 바로 얻을 수 있기 때문에, 편의성을 고려하여 아직까지도 uncertainty 기반의 방법이 많이 쓰인다고 한다.
의견
개인적으로 exploitation이 문제가 될거라는 생각은 잘 안해봤기에 새롭게 고려할 사항인 것 같다. 단순히 margin 정보이기만 하면 완전히 새로운 정보이기 때문에 중요할거라고 생각했는데.
논문을 안읽어서 모르는데, Exploration-P가 contrastive learning처럼 DL에 영향을 줘서 학습이 되는건지 아니면 현재 feature space상에서 평가만 하여 샘플링을 하는건지가 궁금하다. contastive learning을 같이 하면서 AL strategy에서도 저 방법을 써야 시너지 효과가 나지 않을까?
그리고 adversarial active learning은 처음 듣는데 이쪽도 찾아봐야겠다.
3.1.3 Deep Bayesian Active Learning (DBAL).
역시 MC dropout이 빠질 수 없다!
잠깐 스킵하고 딴것부터 읽으려고 한다.
3.1.4 Density-based Methods.
original dataset을 대변할 수 있는 'core set'이라는 게 있을까? 이런 data distribution의 관점에서 시작하는 방법이다.
Farthest First Active Learning (FF-Active)이 있는데, 아까 Exploration-P와 유사하다.
그리고 Core-set 논문도 여기 포함된다. 그 K-center problem을 푸는 그 논문. 단, 이 논문은 unlabeled data들에 대해 distance matrix를 만들어줘야하기 때문에, 데이터가 많을수록 computation이 많이 든다.
Active Palmprint Recognition, Discriminative Active Learning 같은 논문도 있다고 한다. 둘다 active learning을 binary classification task로 보고 한다고 한다.
상대적으로 기법이 많지는 않아서 좋은 연구주제일수 있다고 한다.
3.1.5 Other methods
3.2 Insufficient Data in DAL
3.3 Common Framework DAL
4. VARIOUS APPLICATIONS OF DAL
5. DISCUSSION AND FUTURE DIRECTIONS
~나중에 이어서 작성~
지금까지 읽은 것 중에서 고려할 사항 정리
1.
일단은 batch mode active learning.
딥러닝이니까 어쩔 수 없잖아?
2.
exploitation, exploration을 같이 고려하자.
매우매우 기초적인 방법으로 각각 logit의 entropy, variance로 정량화할수 있을 것이다. 다른 방법은?
3.
pipeline inconsistency 문제를 고려하자. (예시. Learning loss)
4.
semi supervised learning를 활용해보자.
이건 내가 지금 고려중이라 써놓은 것
'AIML 분야 > self supervised, Learning Theory 등' 카테고리의 다른 글
| [Continual Learning 조사 1] 마구잡이로 찾아보는 글 (0) | 2022.03.31 |
|---|---|
| [2021.03.08 연구노트] KD, Semi-Supervised Learning에 대한 고민 (0) | 2021.03.08 |
| [Active Learning] 서베이 하기 (0) | 2021.02.23 |
| [연구 노트] Deep Active Learning 베이스라인 코드 리뷰 + 내 연구 (0) | 2021.01.15 |
| Self-Supervised Learning 몰라서 공부하는 글 (0) | 2020.12.21 |



댓글